人工智能的蓬勃发展对算力提出了更为严苛的挑战。在芯片计算能力方面,GPU相较于CPU,其浮点计算能力优越,大约高出10倍,因而深受人工智能领域的青睐。此外,深度学习加速框架通过进一步优化GPU性能,进一步提升了其在神经网络计算上的速度。随着人工智能技术的持续进步,计算芯片逐渐从通用向专用演变,DPU、TPU、NPU等专用芯片应运而生,并在各自的应用领域内发挥着日益举足轻重的作用。
01 CPU
CPU,即中央处理单元(Central Processing Unit),作为计算机的核心部件,堪称计算机的“大脑”,它掌控着计算机的整体运作。其内部结构错综复杂,却可概括为运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)以及它们之间相互沟通的数据、控制和状态总线。简言之,CPU就是由计算单元、控制单元和存储单元共同构成,其架构图如下: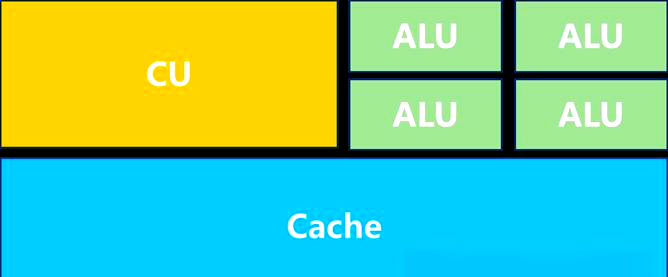
其中,计算单元专注于执行算术运算、移位操作,以及地址运算和转换;存储单元则负责保存运算过程中生成的数据和指令;而控制单元的任务是对指令进行译码,并发出执行每条指令所需的操作控制信号。
接下来,我们将探讨另一种关键处理器——GPU。
GPU,即图形处理单元(Graphics Processing Unit),起初主要用于个人电脑、工作站、游戏机以及平板电脑、智能手机等移动设备中的绘图运算。从其架构图中可以明显看出,GPU的构造较为简洁,拥有众多计算单元和流水线,非常适合处理大量类型统一的数据。
但GPU无法单独工作,它必须依赖于CPU的控制调用才能发挥作用。而CPU则能单独运作,处理复杂的逻辑运算和多样化的数据类型。然而,当面临需要处理大量类型统一的数据时,CPU会调用GPU来进行并行计算,以提升效率。
英伟达作为知名的GPU供应商,在全球市场上占据了高达87%的份额。其推出的A100和H100系列GPU在AI训练和高性能计算领域展现卓越性能,特别是在深度学习和矩阵乘法方面进行了针对性优化,显著提升了训练速度。国内众多云服务提供商都选用A100芯片来支持其数据中心的AI计算需求。
那么,为什么在AI运算方面,GPU相较于CPU更占优势呢?这主要是因为CPU和GPU在设计和性能上存在根本差异。CPU在整型计算上表现出色,但浮点计算能力相对较弱,并不擅长处理大规模的AI模型。而AI运算,尤其是深度学习模型的训练和推理,主要涉及矩阵和张量运算,对浮点运算性能的要求极高。相比之下,GPU专为处理高密度浮点运算而设计,拥有众多计算单元,能够同时处理大量数据,非常适合并行计算。因此,在AI运算方面,GPU的整体性能优于CPU。
接下来,我们将探讨另一种处理器——DPU。
DPU,即数据处理单元,是一种可编程处理器,集成了处理核心、硬件加速器以及高性能网络接口。它专为处理大规模数据工作负载而设计,涵盖数据传输、处理、保护、压缩及加密等多个方面,如数据中心的网络、存储和安全操作。DPU的应用广泛,包括AI与机器学习、大数据分析、视频转码与流媒体处理、网络流量管理以及存储I/O加速等。
与CPU和GPU协同工作时,DPU能显著增强计算能力,分担网络和通信工作负载,从而释放资源专注于应用程序处理。其处理核心与硬件加速器的结合,使得DPU能高效处理大规模数据工作负载,降低处理延迟。无论是云环境内的大规模数据任务,还是驱动AI、深度学习等数据密集型应用,DPU都能轻松应对,灵活适应不断增长和复杂化的工作负载。
此外,DPU的冗余和高可用性特性增强了其可靠性,确保在硬件故障时关键数据处理仍能保持连续性。通过为CPU分担高度复杂的处理任务,DPU有助于减少数据中心内的硬件数量和管理成本。
DPU供应商提供多种类型的产品,以满足企业客户的不同需求和技术要求。主要分为基于SOC、ASIC和FPGA的三种类型,每种类型都经过精心定制,以适应特定用例或客户系统。
TPU,即张量处理单元,其命名灵感源于Google的TensorFlow开源深度学习框架。
这种处理器专为AI工作负载而设计,特别是在矩阵运算方面表现出色。在AlphaGo项目中,TPU助力人工智能驱动的Go玩家在2016年击败了围棋顶尖选手李世石,同时也在谷歌搜索和街景等应用中发挥着关键作用。如今,随着深度学习技术的广泛应用,TPU已走出Google,成为众多企业和研究机构的必备工具。
计算芯片的演进趋势是从通用型向专用型转变。尽管CPU和GPU功能强大,但专用集成电路(ASIC)如TPU在特定任务上的效率更高。TPU专为AI模型运算而设计,能够处理独特的矩阵和矢量运算,而GPU则更适合处理图像信息。因此,在神经网络算法方面,TPU的性能优势更为明显,能够达到3至5倍的性能提升。此外,在功耗和尺寸方面,TPU也表现出色,非常适合深度学习模型的大规模部署。
展望未来,TPU在AI领域的应用前景将更加广阔,有望成为领先GPU的新一代计算引擎。
NPU的诞生正是为了克服CPU和GPU在AI计算方面的局限。
CPU通用性强且逻辑处理能力卓越,但并行计算能力稍显不足。GPU则在并行计算和大数据处理上表现出色,特别是图像处理方面。然而,这两种处理器在应对特定的AI计算任务时,仍面临效率和能耗的挑战。正因如此,NPU应运而生,旨在更高效地处理深度学习和机器学习中的大规模矩阵运算等复杂任务。
NPU的架构经过精心设计,专门针对神经网络计算进行优化。它专注于执行深度学习所需的矩阵运算、卷积运算等操作,并配备了专门的硬件加速器,如张量加速器、卷积加速器,以模拟人脑神经元和突触的工作方式。通过大规模并行处理单元和高效的互联结构,NPU能实现对深度神经网络中复杂计算的快速加速。在操作视频、图像等海量多媒体数据时,NPU展现出了卓越的性能。
与CPU的单线程优化和GPU的并行计算优化相比,NPU在特定AI任务中的表现更为出色。例如,它能够高效处理复杂的神经网络推理,从而提升AI应用的实时性和响应速度。NPU的性能通常以TOPS(每秒万亿次操作)为单位进行衡量,反映其在处理AI任务时的效率和性能。
此外,NPU在能耗方面相较于CPU和GPU具有显著优势,这在移动设备中的应用显得尤为突出。例如,OPPO自研的NPU在相同功耗下的性能是GPU的上百倍。
展望未来,NPU在物联网设备和人工智能边缘计算等领域的应用前景广阔。AI手机和AI PC有望成为未来手机和个人电脑的重要升级方向,而NPU无疑是这些产品中不可或缺的硬件增量方向之一。
在AI领域,NPU的应用广泛且高效。它可以被用于实现人脸识别、语音识别等关键功能,使得这些复杂的任务能够在本地设备上得到迅速且高效的执行,无需借助远程的云端计算。这一优势不仅显著提升了处理速度,还降低了因数据传输而产生的延迟和潜在安全风险。

