本文介绍来自浙江大学杨易团队和华为联合提出的最新科研成果 - MIGC。MIGC论文中提出了一个具有实际应用价值和富有挑战性的Multi-Instance Generation (MIG) task。MIG task要求生成图像中的每个实例物体需要符合用户指定的位置描述和文本描述。MIGC基于分而治之的思想将复杂的MIG拆解为目前SD已经处理很好的Single-Instance Generation子任务,并通过整合子任务的解来得到原始MIG的解。作为一个即插即用的控制器,MIGC可以极大地增强现在广泛使用的SD模型在方位、属性、数量维度上的控制能力。 论文题目:
MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis
论文链接:
https://arxiv.org/abs/2402.05408
代码链接:(SD1.x版本权重、GUI已经开源)
https://github.com/limuloo/MIGC
在线试玩:(不需要你有任何计算资源,使用colab免费额度就可以在线体验)
https://colab.research.google.com/drive/1rkhi7EylHXACbzfXvWiblM4m1BCGOX5-?usp=sharing
COCO-MIG Benchmark(欢迎follow和刷榜)
https://paperswithcode.com/sota/conditional-text-to-image-synthesis-on-coco-1
MIGC应用1,结合LoRA,对指定角色进行细粒度可控的生成
MIGC应用2,结合GUI用户界面,MIGC让您的创作更加可控和便捷!更多应用可以前往github主页查看 COCO-MIG Benchmark榜单, https://paperswithcode.com/sota/conditional-text-to-image-synthesis-on-coco-1
1.1 以往文生图方法的局限性 最近两年,文生图已经成为最热门的AI研究方向之一。借助强大的文生图模型,用户只需要提供文字描述就能将想象具现化。如图0所示,当前文生图模型在生成 单实例 的情况下已经实现了几乎完美的效果。
图0: 现在文 生图模型处理单实例生成的能力已经非常强大
图1:仅通过文本描述难以精确描述一个复杂的布局。同时,SD1.4 在面对复杂布局描述时根本无法控制布局。
然而,当面对包含复杂布局(Layout)和丰富属性的多实例(Multi-Instance)文本时,现在的文生图模型还难以满足人们的需求。假设我们脑海中想创造的是如图1(a)中布局的图片,我们会发现一个尴尬的地方:仅用语言几乎难以精确地描述我们的目标布局。如图1(b)所示,我构造了一个尽可能符合目标布局的文本并将其输入到当前很火的 stable diffusion1.4[1] 模型中得到了图1(c)的结果。从结果中我们可以看到,SD1.4 在面对复杂布局描述时根本无法控制布局,并且出现了物体丢失的现象(对于出现这个现象的原因,AAE 论文已经有过研究,感兴趣的可以参考一下[2])。同样,如图2所示,就算是 GPT-4也难以理解这种复杂的布局文本描述。
图2:尽管是现在文本理解能力超强的 GPT-4 也无法处理上述复杂布局,生成我们想象中的的图片。
于CVPR2023发表的GLIGEN[3]方法支持Layout+文本的输入形式。如图3所示,GLIGEN在生成的图像中展现了强大的Layout控制能力。然而,我们发现GLIGEN在生成下面的三个行李箱时,出现了属性错误的问题。这一方面是因为GLIGEN所使用的CLIP文本编码器的特性会导致后出现的"suitcase" token会被先出现的"black" token影响从而出现属性泄露问题(文本泄露[4]),另一方面是因为GLIGEN中的Cross-Attention (CA)注意力模块并没有加上显式的属性隔离控制,即带有black属性的token仍然是会有可能影响到下面三个行李箱区域的(空间泄露,这是由于Cross-Attention操作本身没有显式约束)。
图3:以前的布局生图的SOTA方法GLIGEN虽然能生成布局符合我们想象布局的图片,但是每个实例的属性并不准确。
1.3 MIGC能确保方位和属性正确 在了解了上述SOTA方法所面临的文本泄露和空间泄露问题后。我们可以理解一个点:直接将含有【丰富属性】和【复杂布局】的多实例信息一股脑地编码起来并通过Cross-Attention注入到图像特征中是难以保证每个实例的属性正确性的。并且我们把这种要求每个实例都要按照指定位置和文本描述生成的设定具体定义为Multi-Instance Generate(MIG, 多实例生成)。
那么,MIGC是怎么解决上述痛点的呢?回想一下,在图0中我们提到,现在的文生图模型在单实例的场景下已经做到了非常出色的效果。受分而治之的思想启发,我们很容易联想到,我们完全可以将复杂的MIG多实例生成任务拆解成多个简单的单实例生成任务,通过整合子任务的解以得到MIG的解。
举个例子,在处理子任务的时候,生成左下角的“a green suitcase”的时候,我们就只需要输入“a green suitcase”文本而不带着其他实例的属性信息,这就避免了文本泄露。同时,在得到每个子任务的解后,我们又可以根据layout信息,对每个实例的信息进行显式的空间掩码过滤,从而也就避免了空间泄露。如图4所示,结合分而治之这样的思想,我们的Multi-Instance Generation Controller (MIGC)生成了布局+属性完全正确的图像。作为一个即插即用的控制器,我们还可以将MIGC部署在更强大的基础模型RV60B1[5]上得到画质更高的图像。
图4:我们提出的MIGC方法能生成布局准确+属性准确的图像。作为一个即插即用的控制器,MIGC可以无缝配合强大的基础模型RV60B1,生成更加逼真的图像。
1.4 COCO-MIG Benchmark来评测模型方位+属性+数量控制能力 我们把图1~图4这种要求每个实例都按照指定位置和文本描述生成的任务具体定义为Multi-Instance Generate(MIG, 多实例生成)。
在此之前,比较广泛使用的COCO Benchmark(为了和我们的COCO-MIG Benchmark区分开,后续称其为COCO-position benchmark)只关注每个实例能否在指定位置生成而忽略了对每个实例属性是否正确的考查。因此,我们在COCO-position Benchmark的基础上进行了扩展构建了我们的COCO-MIG Benchmark。构造的流程大概就是,我们在COCO-position layout的基础上,为每个实例随机分配了一种具体的颜色属性。
举个具体的例子,图3中GLIGEN输出的图像会被COCO-position当做成功生成,因为确实行李箱都生成出来了。然而,COCO-MIG Benchmark对模型提出了更高的要求,现在不光要行李箱能生成出来,还需要每个行李箱的属性(颜色)是正确的。这也就对模型的控制能力有着更高的要求。
当一个模型模型拥有强大的方位+属性控制能力,那么就可以扩展到强大的数量控制能力,再进一步扩展到更多的实际应用(例如上面展示的实际应用效果图,更多demo可以前往github主页查看)。贴一下COCO-MIG的榜单,欢迎大家来follow和刷榜!
https://paperswithcode.com/sota/conditional-text-to-image-synthesis-on-coco-1?p=migc-multi-instance-generation-controller-for 另外,为了让大家方便查看COCO-MIG中的case和存在的挑战,我在云盘中分享了COCO-MIG采样出来的800个Layout以及MIGC (CVPR2024)、GLIGEN(CVPR2023)、 InstanceDiffusion(CVPR2024)得到的结果。
https://drive.google.com/drive/folders/1UyhNpZ099OTPy5ILho2cmWkiOH2j-FrB
1.5 总结 (1)为了推进视觉生成的发展,我们提出了 MIG 任务,以解决学术界和工业界普遍存在的挑战。同时,我们提出 COCO-MIG benchmark,以评估生成模型的 MIG 能力。
(2)受到分治的启发,我们引入了一种基于分治的 MIGC 方法,通过改善预训练的 SD 模型增强其 MIG 能力。
(3) 我们在COCO-MIG,COCO-Position,DrawBench三个 benchmark 上进行了广泛的实验,结果表明,我们的 MIGC 在属性、方位、数量控制能力上显著超过了之前的 SOTA。
二、方法
2.1 MIG问题定义 给定全局 prompt , bounding boxes 集合 , 其中 , 以及其对应的 description 集合 ,模型需要生成一张图片,使得每一个 box 里的内容都由其对应的 description 描述。
2.2 MIG 的困境 图5:以前sota方法在MIG上的问题 如图5所示,目前 training-free 的算法(box-diffusion ICCV2023[6] 、Multi-DIffusion ICML2023[7] 、TFLCG WACV2023[8] )都有严重的物品消失、属性泄露的问题,而虽然 GLIGEN[3] 在物品消失上有很好的缓解,但是其还是有比较严重的属性泄露问题。
文本泄露 :Structure diffusion[4]这篇论文发现了 CLIP 的 mask-attention 会导致语义信息从前面的 token 泄漏到后面的 token,比如图3中的例子,后出现的"suitcase" token会被先出现的"black" token影响从而出现属性泄露问题,从而就呈现出来了,很多行李箱变成了黑色的问题。
空间泄露 :Cross-Attention (下文简称 )在文本和图像特征交互的时候并没有加上显式的属性隔离控制,例如图3中的例子,带有"black"属性的token仍然是会有可能影响到下面三个行李箱区域的(空间泄露,这是由于Cross-Attention操作本身没有显式约束),同样我们也可以发现"yellow"这个属性也影响到了周围的地板区域。
2.3 MIGC 的整体框架 图6:MIGC的overview。MIGC作为一个即插即用的控制器,可以安装在SD Unet的Cross-Attention层。确保SD的Cross-Attention层得到正确的各个实例属性正确的结果(用MIGC论文的描述就是shading results)。 如图6所示,MIGC受分而治之的思想启发,将复杂的MIG多实例生成任务在Stable Diffusion的Cross-Attention(CA)层拆解成多个简单的单实例生成任务,通过整合子任务的解以得到MIG的解。在处理子任务“a blue cat”的时候,我们就只需要输入“a blue cat”文本而不带着"a green dog"的属性信息,这就避免了文本泄露。同时,在得到每个子任务的解后,我们又可以根据layout信息,对每个实例的信息进行显式的空间掩码过滤,从而也就避免了空间泄露。通过MIGC的控制,我们可以保证Cross-Attention最终的结果是每个实例属性正确的。
2.4 分而治之---怎么“分" 对于一个包含N个实例的MIG输入,MIGC按照每个实例的 box、description 划分出N个子任务。同时,MIGC把MIG的问题定位在Stable Diffusion的CA层,那么第i个子任务相当于找到一个结果(论文中称其为shading instance),其在对应第i个实例对应区域 的输出应该符合第i个实例的文本描述 。之所以将“分”定位在CA层主要是基于以下几点考虑: (1)CA层是SD中文本和图像特征交互的唯一层,我们只要确保Cross-Attention输出各个实例属性正确的结果,就能很大程度上保证最终输出图像结果的正确性。
(2)为了之后更高效的“治”。在进行N个实例的生成时,分治要求我们解决N个子任务。如果我们直接在网络的最终输出上分解那么将导致我们需要过N次完整的SD Unet,那这个效率是非常低的。而如果我们仅将问题定位在CA层的话,我们只需要过N次CA,而不需要过N次Unet。这将更高效。
(3)为了之后更好的“合”。在网络的中间层融合相比在网络最后输出融合更能得到内聚性更强、更和谐的图像。这一点可以参考图9中,MIGC和Multi-Diffusion[7]的结果对比。Multi-Diffusion就是一种在网络输出层融合的算法。
2.5 分而治之---怎么“治" 图7:MIGC的三个主要模块。(1)Enhancement Attention(EA)。(2)Layout Attention(LA)(3)Shading Aggregation Controller(SAC)。
有一个很 naive 的想法,如图6,我们将 的输出直接乘上一个由 box 组成的 mask,就可以实现对物体的控制了。具体的: 其中, 由第i个实例的文本描述 通过预训练 SD 中的线性映射得到, 是一个由第i个实例的box 构造得到的矩阵,其中在 box 内的为 1,在 box 外的为 0, 表示 Hadamard 积。
物体消失。事实上,SD 初始的噪声极大程度影响了图像的布局[9],如果初始的噪声在 box 内和其对应的 prompt 没有很强的注意力关系,那么就会导致严重的物品消失。 物体融合。对于两个相同 prompt 的 box,如果其位置靠近甚至重合,那么就会导致生成出来的是一个物体。 上述问题引导我们设计出 :如图6,我们结合 resnet、controlnet 的思想,使用 为 得到的结果进行加强。如图7(a), 首先将 CLIP 文本特征连接上 box 位置信息,得到一个新的 grounded embedding ,也就是: 然后 利用 再做一次 cross attention,将其加到 输出的残差 上: 其中, 需要重新训练。在训练阶段, 影响到的区域都会由掩码 提供精确的位置定位,这就很容易让 学到:不论图像特征是什么样的,EA都要输出符合实例描述 的残差添加到原始的CA结果上,从而确保输出在 区域的内容是符合我们子任务的要求的。
2.6 分而治之---怎么“合" 融合的背景 :如图6所示,我们将全局文本输入预训练stable diffusion的CA层并用背景掩码(前景实例掩码并集的补集)过滤得到融合背景。
Layout Attention(LA)学习融合模板 :分治得到的信息是相互独立的,如果直接融合可能会造成保真度降低的情况。如图6所示,MIGC会学习一个融合模板,在此模板的基础上进行下一步的融合。如图7(b), 相当于 image tokens 的一个self-attention,同时,为了防止不同实例box间的语义信息泄漏, 根据Layout编辑了一个 Attention mask,确保一个pixel只能关注到跟它同处于一个实例区域的其他pixel。具体的: SAC实现最后融合 :如图7(c)所示,我们将所有的 用 SAC 模块进行处理,融合为最终的输出。从图8的可视化结果中可以看到SAC会在“Blue cat”的区域分配给“Blue cat”的结果更多权重,在“Green dog”的区域分配给“Green dog”的结果更多权重。 图8:SAC会动态的给每个实例的结果在其对应区域分配权重。
2.7 Loss 首先是Stable Diffusion 原有的重建 Loss:
为了防止背景生成多余的物体,我们设计了 inhibition loss:
其中 表示第 i 个实例在预训练SD的 (训练过程中冻住)中的 attention map,DNR 是一个降噪操作,我们具体实现的时候是将 attention map 背景区域里的值做平均。其动机是:如果背景的 attention map 存在突出的值,那么很容易在背景区域生成新的实例[2],那么就相当于我们要让背景区域尽可能平滑。最终的 Loss 为:
三、实验结果
3.1 COCO-MIG的结果 表1:COCO-MIG 定量结果 图9:COCO-MIG 定性结果
从表1和图9中可以看到,MIGC远超之前的SOTA方法,展示了强大的方位、属性、数量控制能力。更多实验结果可以查看论文原文。
3.2 Ablation Study
表2:对MIGC三个模块的消融实验,定量结果。
表3:对inhibition loss的消融实验,定量结果。
EA 显著提高了成功率,其从 12.10% 提高到了 80.16%,mIoU 也从 29.55 提高到了76.63,AP 从1.89 / 7.64 / 0.49 提高到了 53.03 / 84.05 / 58.67。
L A 可以提高 AP。我们发现,与单独的 SAC 相比,SAC+LA 的 mIoU 有所提高。
inhibition loss 可以显著提高 COCO-Position 中的 AP 指标。我们发现,将 λ 设为 1.0 可以进一步提高 AP 指标,但这会略微导致 FID 下降。因此,我们最终选择损失权重为 0.1。在 COCO-MIG 上,我们观察到 inhibition loss 可以改善 mIoU,特别是在生成具有大量实例的图像时。
图1 0:对MIGC的每个组件的消融实验,可视化对比。
inhibition loss 增强了模型的控制能力。 position embedding 有效缓解了物体融合。
参考文献 [1] High-Resolution Image Synthesis with Latent Diffusion Models
https://github.com/CompVis/stable-diffusion
[2] Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
https://dl.acm.org/doi/abs/10.1145/3592116
[3] GLIGEN: Open-Set Grounded Text-to-Image Generation
https://github.com/gligen/GLIGEN
[4] Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis.
https://github.com/weixi-feng/Structured-Diffusion-Guidance
https://civitai.com/models/4201/realistic-vision-v60-b1
https://github.com/showlab/BoxDiff
https://github.com/omerbt/MultiDiffusion
https://silent-chen.github.io/layout-guidance/
[9] Guided Image Synthesis via Initial Image Editing in Diffusion Model
https://dl.acm.org/doi/abs/10.1145/3581783.3612191
Illustration From IconScout By 22


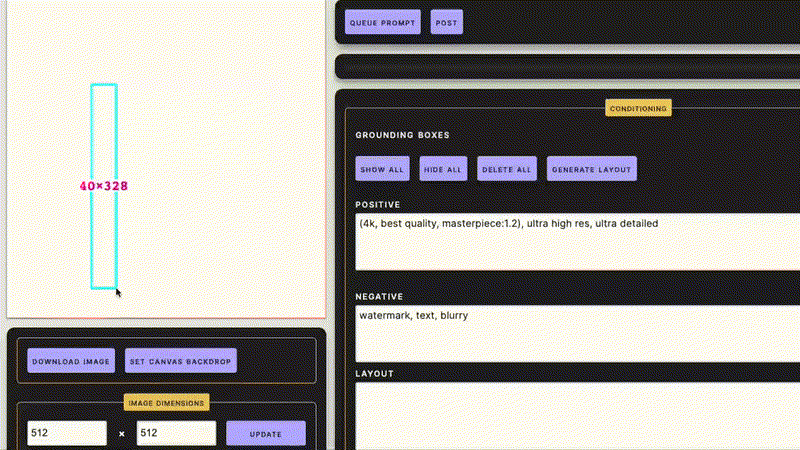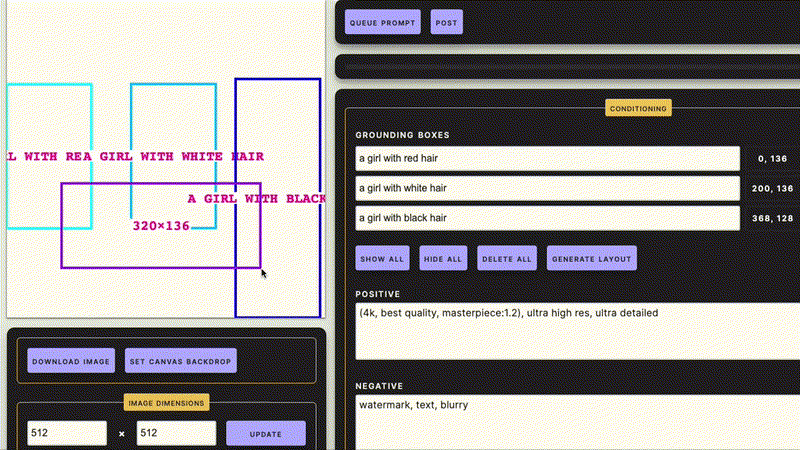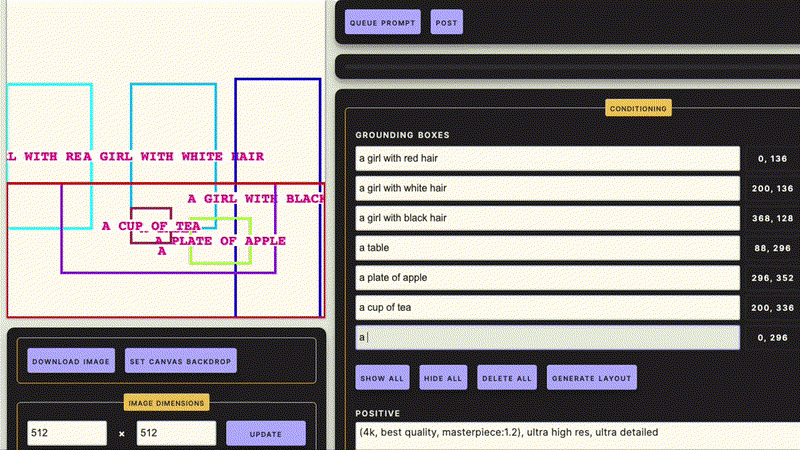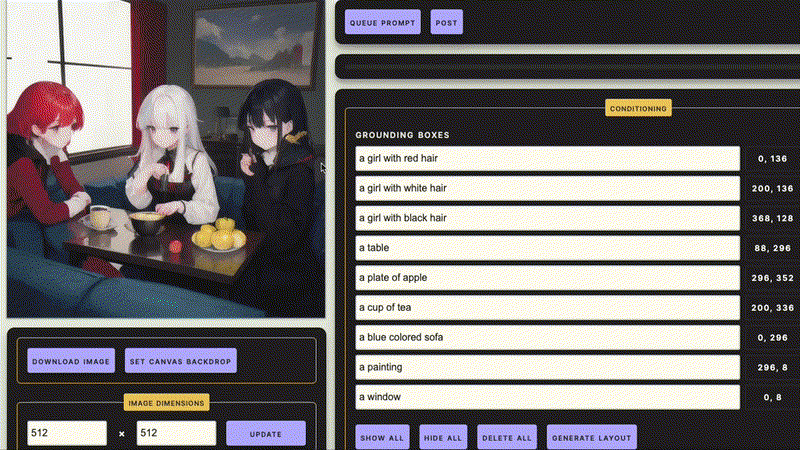
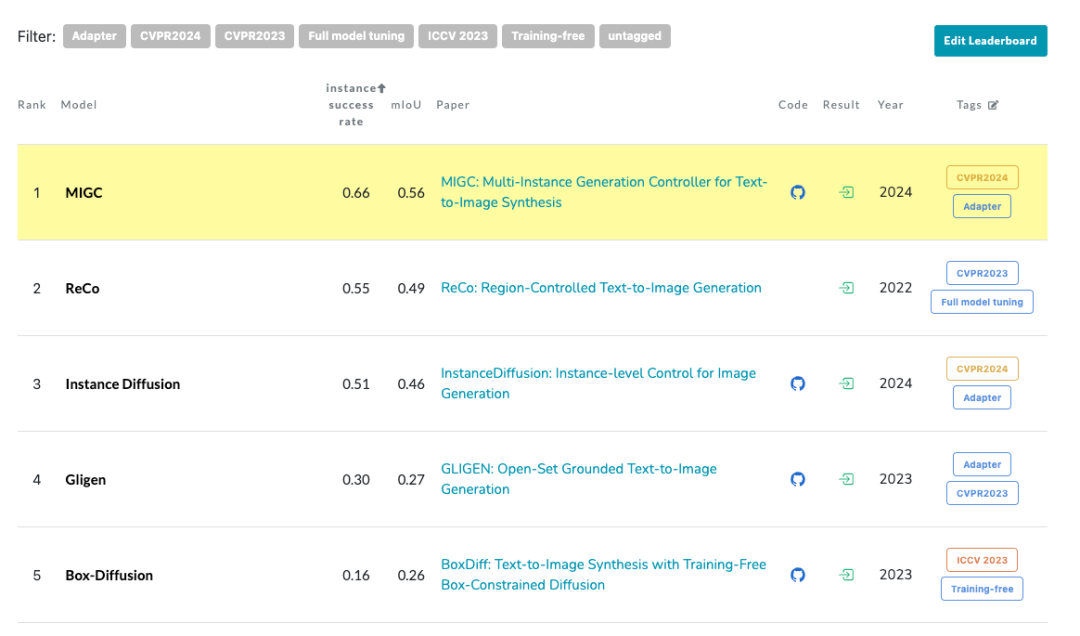 COCO-MIG Benchmark榜单, https://paperswithcode.com/sota/conditional-text-to-image-synthesis-on-coco-1
COCO-MIG Benchmark榜单, https://paperswithcode.com/sota/conditional-text-to-image-synthesis-on-coco-1 图0:现在文生图模型处理单实例生成的能力已经非常强大
图0:现在文生图模型处理单实例生成的能力已经非常强大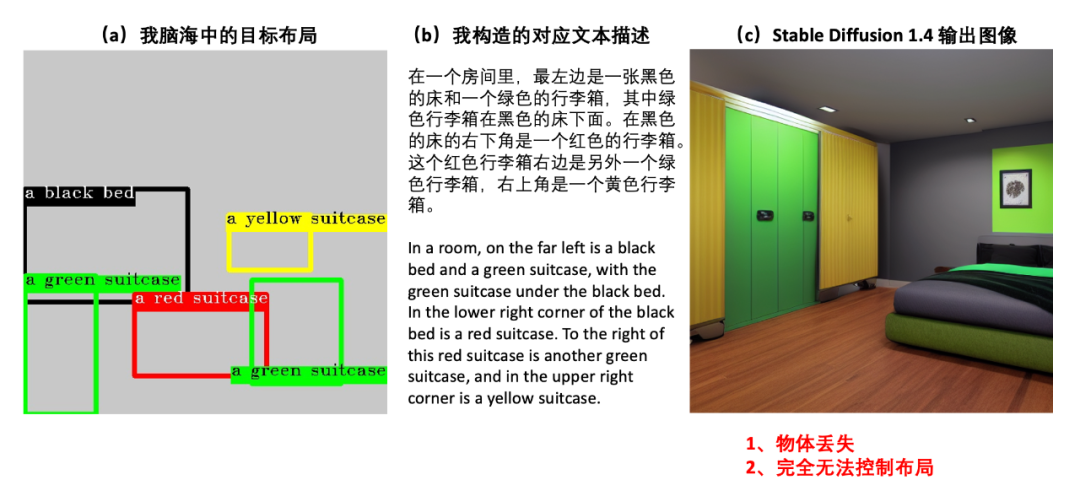
 图2:尽管是现在文本理解能力超强的 GPT-4 也无法处理上述复杂布局,生成我们想象中的的图片。
图2:尽管是现在文本理解能力超强的 GPT-4 也无法处理上述复杂布局,生成我们想象中的的图片。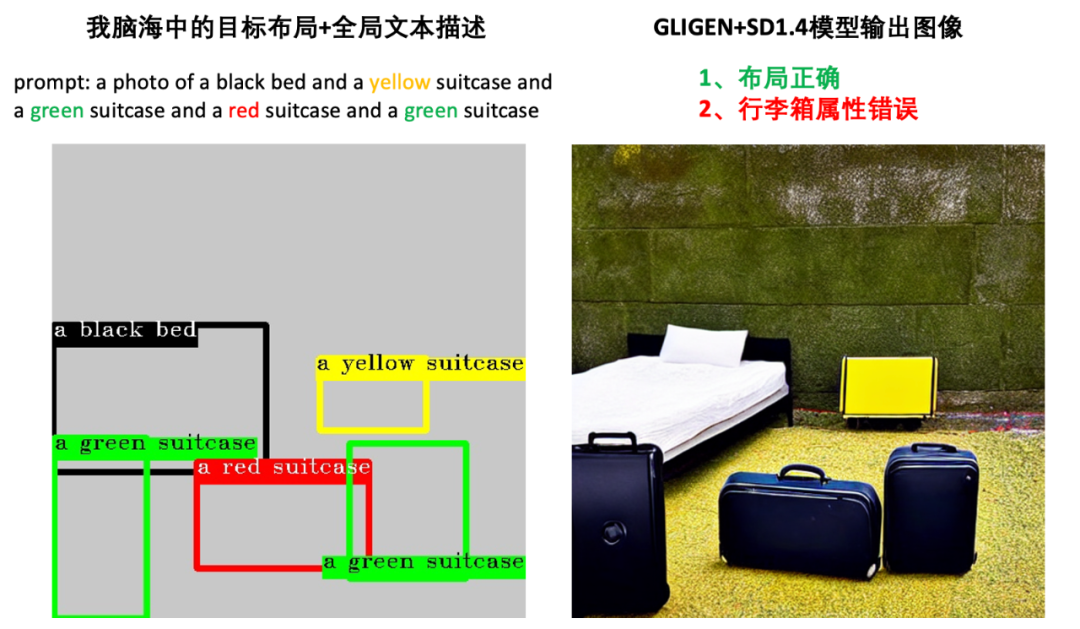 图3:以前的布局生图的SOTA方法GLIGEN虽然能生成布局符合我们想象布局的图片,但是每个实例的属性并不准确。
图3:以前的布局生图的SOTA方法GLIGEN虽然能生成布局符合我们想象布局的图片,但是每个实例的属性并不准确。 图4:我们提出的MIGC方法能生成布局准确+属性准确的图像。作为一个即插即用的控制器,MIGC可以无缝配合强大的基础模型RV60B1,生成更加逼真的图像。
图4:我们提出的MIGC方法能生成布局准确+属性准确的图像。作为一个即插即用的控制器,MIGC可以无缝配合强大的基础模型RV60B1,生成更加逼真的图像。 图5:以前sota方法在MIG上的问题
图5:以前sota方法在MIG上的问题 图6:MIGC的overview。MIGC作为一个即插即用的控制器,可以安装在SD Unet的Cross-Attention层。确保SD的Cross-Attention层得到正确的各个实例属性正确的结果(用MIGC论文的描述就是shading results)。
图6:MIGC的overview。MIGC作为一个即插即用的控制器,可以安装在SD Unet的Cross-Attention层。确保SD的Cross-Attention层得到正确的各个实例属性正确的结果(用MIGC论文的描述就是shading results)。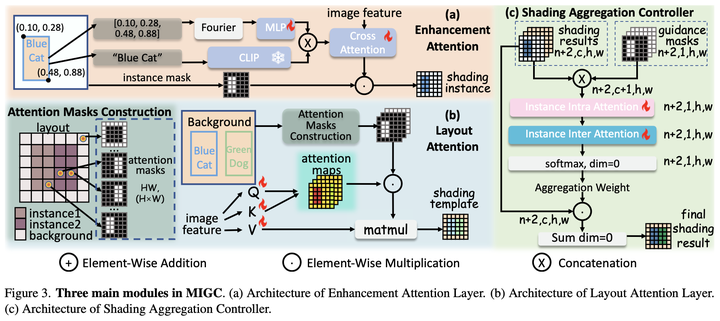 图7:MIGC的三个主要模块。(1)Enhancement Attention(EA)。(2)Layout Attention(LA)(3)Shading Aggregation Controller(SAC)。
图7:MIGC的三个主要模块。(1)Enhancement Attention(EA)。(2)Layout Attention(LA)(3)Shading Aggregation Controller(SAC)。



 图8:SAC会动态的给每个实例的结果在其对应区域分配权重。
图8:SAC会动态的给每个实例的结果在其对应区域分配权重。


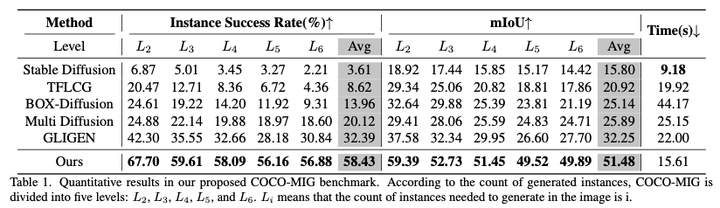 表1:COCO-MIG 定量结果
表1:COCO-MIG 定量结果 图9:COCO-MIG 定性结果
图9:COCO-MIG 定性结果

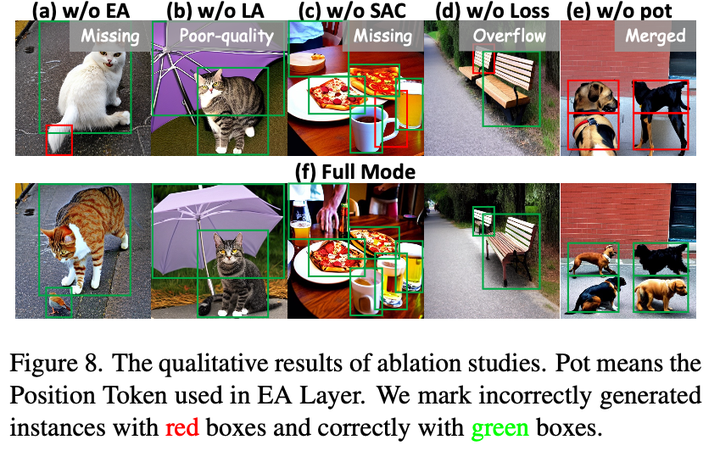 图10:对MIGC的每个组件的消融实验,可视化对比。
图10:对MIGC的每个组件的消融实验,可视化对比。
