关注我带你了解科技领域最新的技术与产品
Model Ops是用于管理和运行正在使用的模型的程序和设备的集合。ML 团队与 DevOps 团队一起在生产中部署每个模型。
 不断推出各种新应用、云服务和其他技术的快速实施,使得IT环境变得太复杂,超出了人类的处理能力,对利润产生了负面影响。尽管公司在人工智能上投入了大量资金,但在竞争激烈的市场上追求数字化转型仍然很困难。他们无法简化所有组织模型,这使得很难从这些模型中获得有价值的见解并做出明智的商业决策。
不断推出各种新应用、云服务和其他技术的快速实施,使得IT环境变得太复杂,超出了人类的处理能力,对利润产生了负面影响。尽管公司在人工智能上投入了大量资金,但在竞争激烈的市场上追求数字化转型仍然很困难。他们无法简化所有组织模型,这使得很难从这些模型中获得有价值的见解并做出明智的商业决策。
在传统的封闭环境中,将所有可用模型从开发区域扩展到CI/CD流水线再到部署区域,对DevOps团队来说可能是一个具有挑战性的过程。当你不得不监控和管理所有这些模型在生产环境中的性能、漂移、偏差和其他风险时,这个挑战变得更加困难。而且还必须遵守国际和本地法规,直到模型退化或被淘汰。
(Model Ops)解决了可扩展性的问题,通过将所有人工智能/机器学习和决策模型在生产中实现运营化。它还专注于在机器学习生命周期中监控和治理模型。使用模型运营自动化所有这些过程,可以增加可观察性,并帮助企业更好地专注于其商业目标。
让我们在这篇博客中详细讨论一下模型运营以及它们如何帮助企业在不影响投资回报率的情况下克服与人工智能实施相关的挑战。
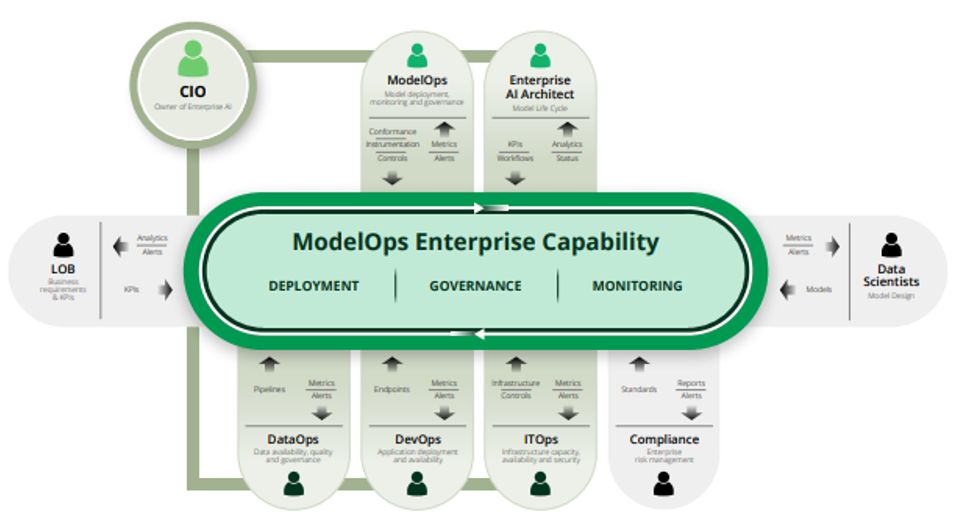
Model Ops组织中的机器学习团队确定业务目标并与DevOps团队一起开发、验证和部署每个模型到生产环境中。但是缺乏适当的方法。
扩展整个企业中的所有模型并在其机器学习生命周期内进行管理。创建可靠且自动化的CI/CD机器学习部署流水线,以简化模型部署过程监控生产中的模型,并确保满足AI模型合规性标准。解决这些问题的一个实用解决方案是“模型运营”。它是一个为人工智能组织实现运营化的框架。模型运营可以通过自动化部署、监控模型、提供端到端治理以及持续改进组织中创建的数据分析模型来简化机器学习/人工智能模型生命周期。
Model Ops与ML运营的比较ML运营是一个数据科学平台,旨在简化构建、训练和部署机器学习模型以及在生产环境中管理和监控模型性能的过程。它结合了机器学习、软件开发和运营,使组织能够在生产环境中提供高质量的模型,并缩短上市时间,提高准确性。
Model Ops是一组为生产中的模型提供治理和运营的实践和工具。这包括使组织能够更好地部署、监控和管理机器学习模型,具有更大的可见性、控制和自动化。它帮助组织确保模型可靠、性能良好,并符合最佳实践和法规要求。
ML运营自动化了从创建模型到部署和监控模型的机器学习生命周期。它还改善了数据科学家和运营团队之间的协作,帮助确保模型以安全高效的方式部署和维护。
Model Ops通过利用基于数据的模型和高级分析来提高企业的运营效率,重点是提供可操作的洞察力,用于优化决策和整体业绩。
ML运营专注于促进数据科学家和开发、运营、生产环境中的IT团队之间的协作,以快速可靠地部署机器学习模型,跟踪这些模型的性能,并快速进行改进,以最大化其商业价值。
Model Ops帮助企业领导者了解实现所需关键绩效指标(KPIs)的各种方式,使用准确且公正的数据科学模型。企业领导者可以确保充分利用人工智能解决方案,并提供反馈以帮助完善和改进人工智能解决方案。
Model Ops的商业优势降低成本:模型运营通过自动化模型的部署、管理和监控,帮助组织降低人工智能/机器学习模型的成本。这有助于减少部署和管理模型所需的手动工作和时间,以及减少手动调试和故障排除的成本。
此外,模型运营提供了自动化的监控和警报功能,使团队能够实时检测和解决问题,降低停机时间和相关损失的成本。
可重复性:自动化机器学习(ML)工作流的主要优势之一是它在许多方面提供了可重复性,从数据版本管理到模型版本管理用于模型运营。这对于机器学习的工业应用至关重要,其中必须不断监控模型性能并提高效率。
自动化ML工作流的另一个好处是可以自动化重复性任务,如数据预处理和模型调优。自动化工作流还可以帮助管理实验跟踪和结果存储,从而在尝试重现先前结果或跟踪ML项目进展时节省宝贵时间。
改善决策:模型运营通过全天候监控、重新训练和定期部署模型来确保模型始终更新和准确。这使得企业能够基于数据做出明智的决策,并自信地向利益相关者展示。
通过自动化决策,企业可以消除对人类直觉的需求,并确保决策与公司的目标和目标保持一致。
增强安全性:模型运营可以帮助检测和分类网络威胁,识别恶意行为,并提供警报和事件以解决问题,以免对业务产生影响。此外,这些模型可以用来创建自动化系统,可以监视网络并检测任何可疑活动,并确保数据的质量和完整性。这对于依赖于关键任务的人工智能的组织来说至关重要。
Model Ops的实施要将模型从业务理念转化为市场产品,需要进行多个步骤和过程。
创建与模型业务目标相一致并符合合规标准的治理框架。确定您想通过人工智能解决的问题,并评估模型是否能够以最佳时间成本比帮助企业实现其目标。确定项目中涉及的成员的角色和责任。选择模型的算法、超参数和特征工程确定用于训练模型的数据集,并确保所有用于模型训练和测试的数据都具有高质量并安全存储。构建模型或重用以前模板的代码,并通过调整超参数来验证模型创建自动化的CI/CD流水线,以简化模型测试和部署过程。定期监控和维护模型,以确保模型的性能符合预期

