

“分享兴趣,传播快乐,增长见闻,留下美好! 大家好,这里是小编。欢迎大家继续访问学苑内容,我们将竭诚为您带来更多更好的内容分享。
"Share interest, spread happiness, increase knowledge, and leave a good impression! Hello everyone, this is Xiaobian. Welcome to continue to visit the content of Xueyuan, and we will wholeheartedly bring you more and better content to share.
判别分析是多元统计分析中用于判别样本所属类型的一种方法。它要解决的问题是在研究对象用某种方法已分成若干类的情况下,确定新的观察数据属于已知类别中的哪一类。判别分析是应用很强的一种多元统计分析方法。如在经济学,根据国民收入、人均工农业产值、人均消费水平等多种指标来判定一个国家的经济发展程度所属类型。医生对病人病情的诊断,需要根据观测到病症(如体温、血压、白血球数等)判断病人患何种病等。
Discriminant analysis is a method used to distinguish the type of samples in multivariate statistical analysis. The problem to be solved is to determine which category the new observation data belongs to when the research object has been divided into several categories by some method. Discriminant analysis is a multivariate statistical analysis method with strong application. For example, in economics, the type of economic development of a country can be determined according to national income, per capita industrial and agricultural output value, per capita consumption level and other indicators. The doctor's diagnosis of the patient's condition needs to judge the patient's disease according to the observed symptoms (such as temperature, blood pressure, white blood cell count, etc.).
判别分析的假设:(1)观测变量服从正态分布;(2)观测变量之间没有显著的相关性;(3)观测变量的平均值与方差不相关;(4)观测变量应是连续变量,因变量(类别或组别)是间断变量;(5)两个观测变量的相关性在不同类中是一样的。
The hypothesis of discriminant analysis: (1) the observed variables obey normal distribution; (2) There is no significant correlation between observed variables; (3) The mean value of the observed variables is not correlated with the variance; (4) The observation variable shall be continuous, and the dependent variable (category or group) shall be discontinuous; (5) The correlation of the two observed variables is the same in different classes.
在判别分析的各阶段应该把握以下原则:(1)事前组别(类)的分类标准(作为判别分析的因变量)要尽可能地准确和可靠,否则会影响判别函数的准确性,从而影响判别分析的效果。(2)所分析的自变量应是因变量的重要影响因素,应该挑选既有重要特征又有区别能力的变量,达到以最少的变量实现高辨别能力的目的。(3)初始分析数据(作为训练集的个案数)不能太少。
At each stage of discriminant analysis, the following principles should be followed: (1) The classification criteria (as the dependent variable of discriminant analysis) of the prior group (category) should be as accurate and reliable as possible, otherwise the accuracy of the discriminant function will be affected, thus affecting the effect of discriminant analysis. (2) The independent variable to be analyzed should be an important influencing factor of the dependent variable. Variables with both important characteristics and distinguishing ability should be selected to achieve the goal of high discrimination with the least number of variables. (3) The initial analysis data (the number of cases as the training set) should not be too small.
一般来说,判别分析的分析步骤有:1.计算特征值。2.建立判别函数。3.确定判别准则。4.检验判别效果。5.分类。
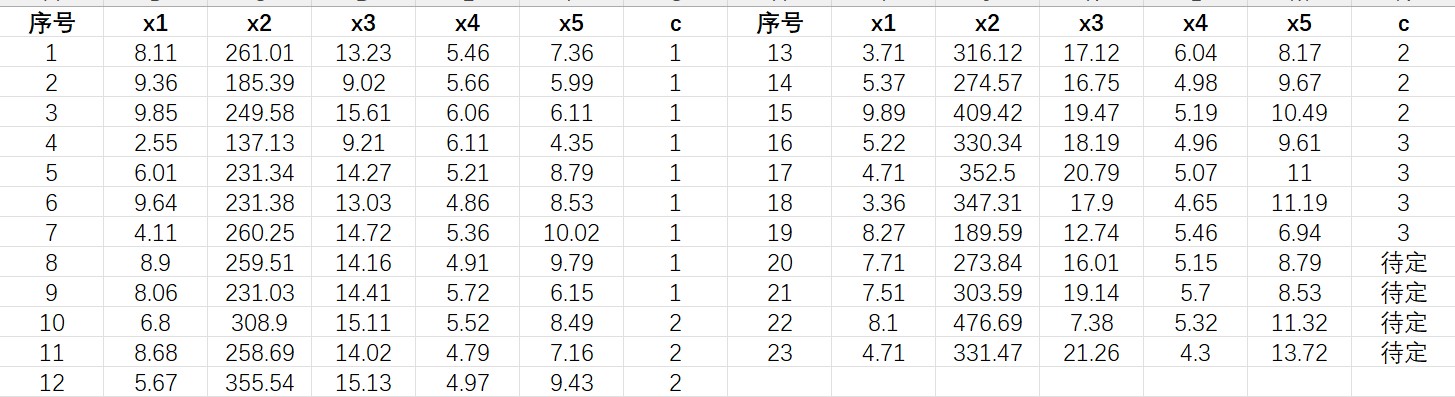
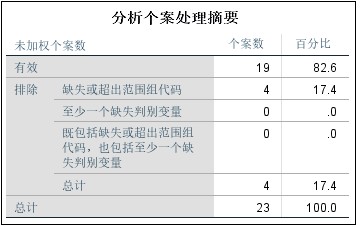
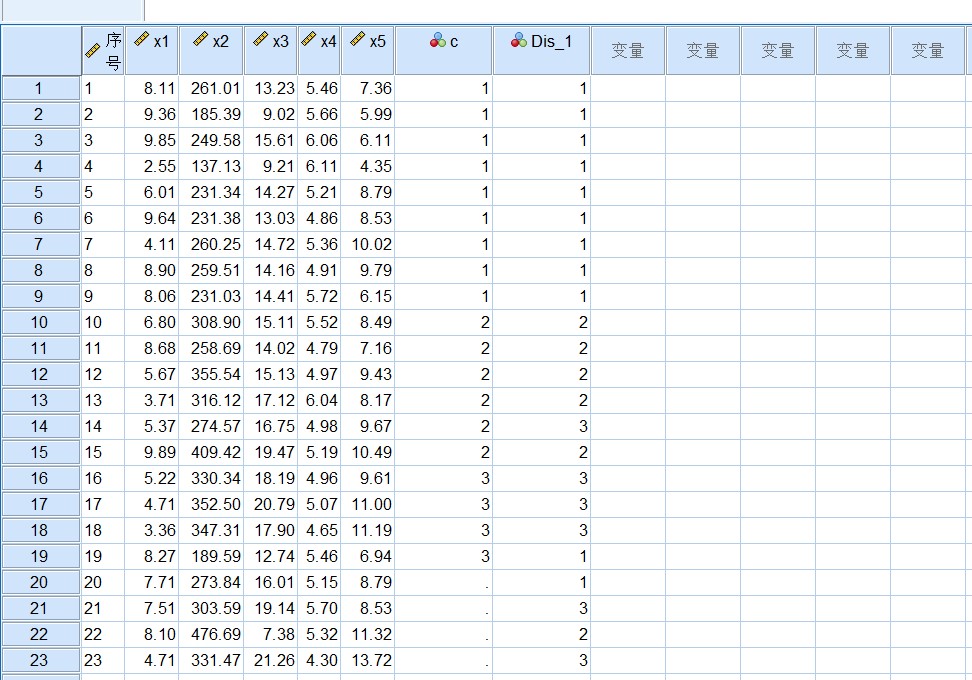
下表是健康人(c=1)、硬化症患者(c=2)和冠心症患者(c=3)三种人群的心电图的5个指标(x1~x5)数据,其中有19个样本是确定的分类,另又测出4个人的相关指标,试根据确定分类的样本对未确定的样本进行分类。
Generally speaking, the analysis steps of discriminant analysis are as follows: 1. Calculate eigenvalues. 2. Establish discriminant function. 3. Determine the criteria. 4. Test the discrimination effect. 5. Classification.
The following table is the data of five indicators (x1~x5) of ECG of healthy people (c=1), patients with sclerosis (c=2) and patients with coronary heart disease (c=3). Among them, 19 samples are determined for classification, and the relevant indicators of 4 people are measured. Try to classify the undetermined samples according to the samples determined for classification.
第一步,分析并组织数据,由于部分样本已经有分类标记,还有几个待分类样本。这显然属于根据已知分类样本的信息对未分类样本进行分类的情况,用判别分析进行处理。按表所示,建立7个变量。分别是“序号”、“x1”、“x2”、“x3”、“x4”、“x5”和“c”,均为数值型变量。输入数据,对第20条~第23条的类别“c”变量,不填数据,作为缺失值处理并保存。
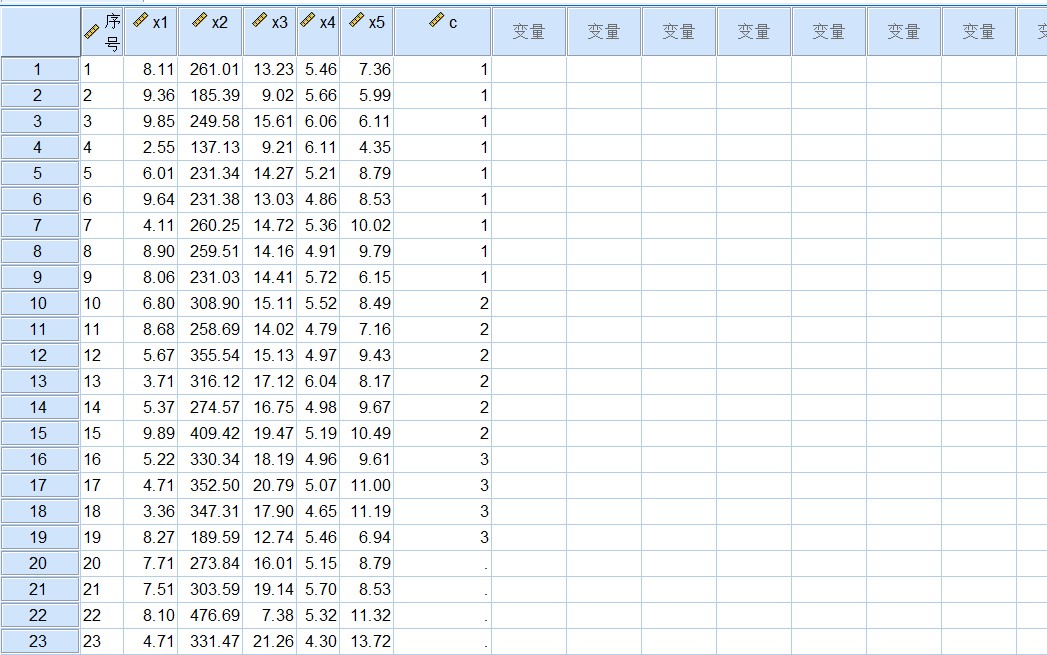
The first step is to analyze and organize the data. Since some samples have classification marks, there are still several samples to be classified. This obviously belongs to the case that the unclassified samples are classified according to the information of the known classified samples and processed by discriminant analysis. Create 7 variables as shown in the table. They are "sequence number", "x1", "x2", "x3", "x4", "x5" and "c", which are all numerical variables. Input data. For category "c" variables in Articles 20 to 23, do not fill in data, and treat them as missing values and save them.
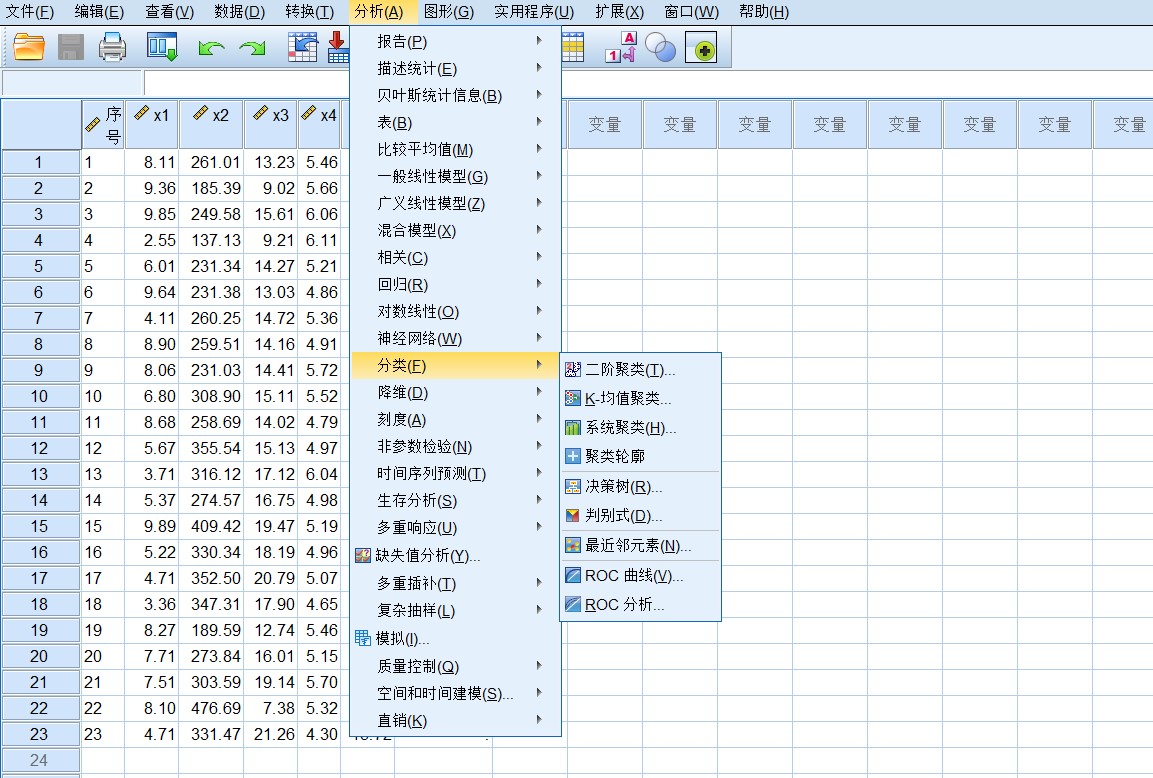
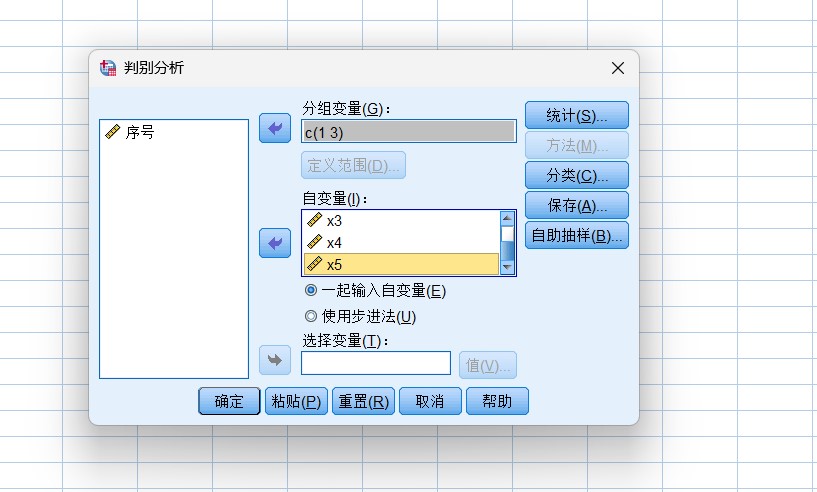
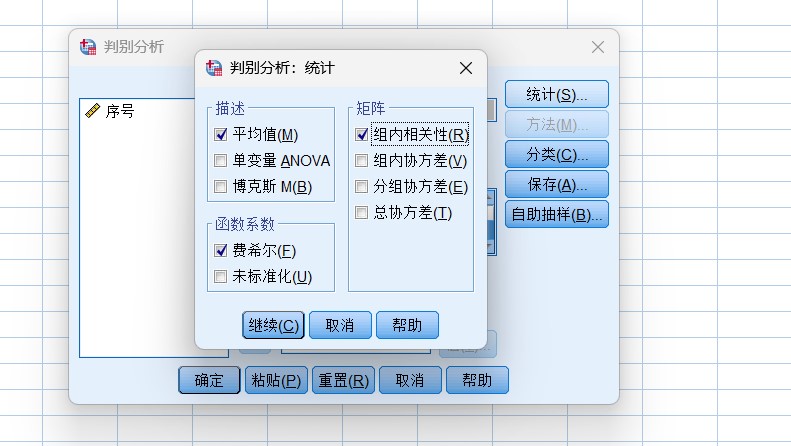
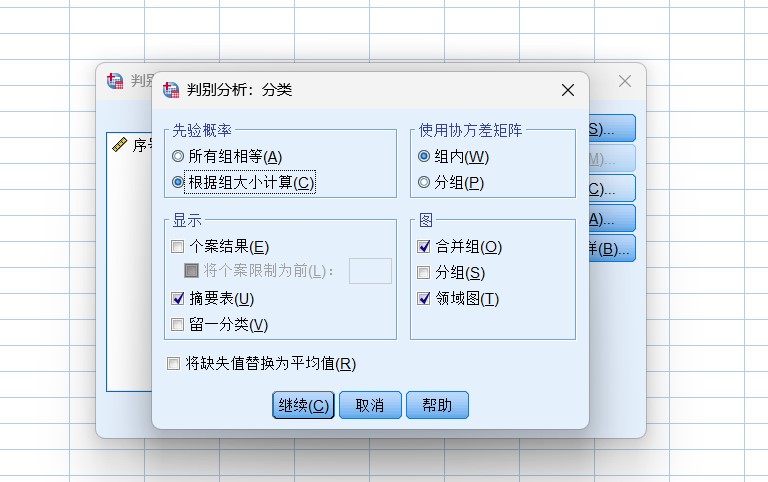
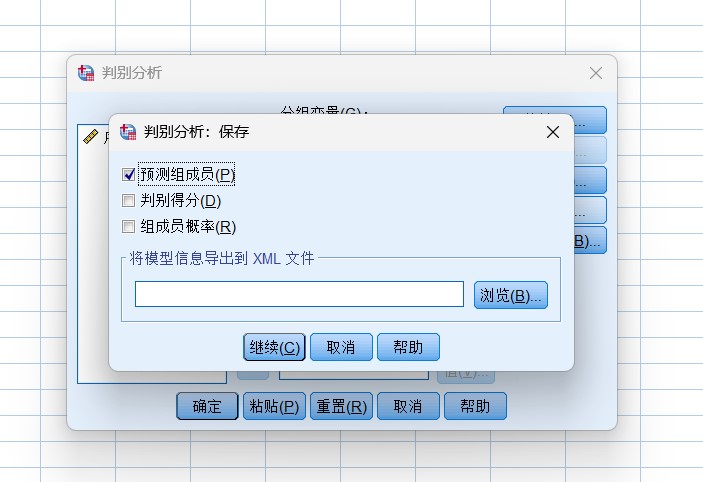
第二步,进行判别分析设置,按下图所示进行判别分析设置。
The second step is to set the discriminant analysis as shown in the following figure.
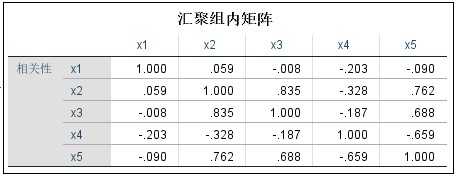
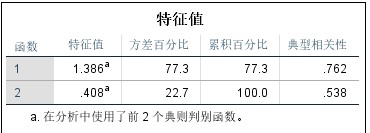
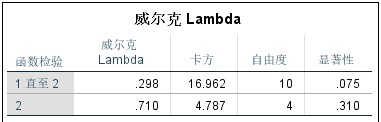
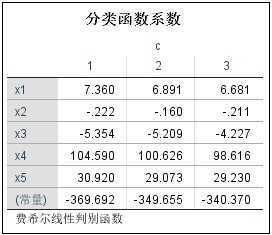
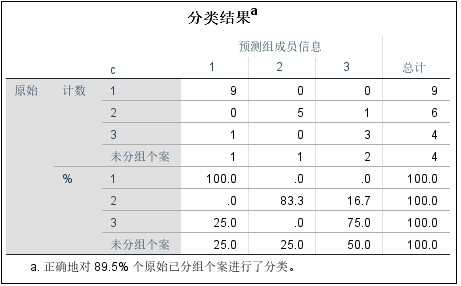
第三步,主要结果与分析,下图即是分析后SPSS的输出结果。
The third step is the main results and analysis. The following figure is the output of SPSS after analysis.



下期预告:本期,我们学习了
判别分析的理论知识和基础运用。
下一期,我们将会进入
主成分分析和因子分析的章节。


今天的分享就到这里了
如果您对今天的文章有独特的想法
欢迎给我们留言
让我们相约明天
祝您今天过得开心快乐!
That's all for today's sharing. If you have unique ideas about today's article, please leave us a message. Let's meet tomorrow. I wish you a happy day today!
参考资料:百度百科,《SPSS 23 统计分析实用教程》
翻译:百度翻译
本文由learningyard新学苑原创,部分文字图片来源于他处,如有侵权,请联系删除。

