
当然啦,刚发布之时由于网友们对ADA架构了解并不足够的多,所以相对的低规格与7K的定价并不太理想,因此网友对这块新卡的印象不怎么好。之后老黄顺就玩家们的要求,降价,改型号,因此才会有RTX 4070 Ti的出现。现在RTX 4070 Ti正式发布,性能解禁之后,相信大家开始懂老黄的,6499元的零售报价,不少网友大叫“真香”。今天我们为大家带来技嘉GeForce RTX 4070 Ti GAMING OC 12G显卡新品评测。
NVIDIA GEFORCE RTX 4070 Ti显卡规格

在测试之前,我们先来看一下NVIDIA GEFORCE RTX 4070 Ti显卡的详细规格,核心代号为AD104-400,Ada Lovelace架构下的第三款核心,其规格相比AD102与AD103核心相对较弱些。而小型核心的设计,使用AD104核心面积只有295mm2,比上代GA104核心的392mm2面积少了约24%,但其核心规格与显存容量都要更高。
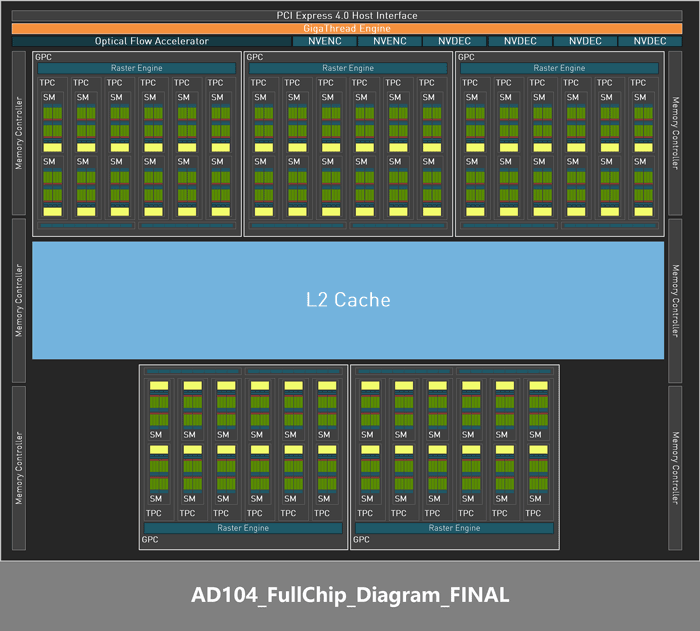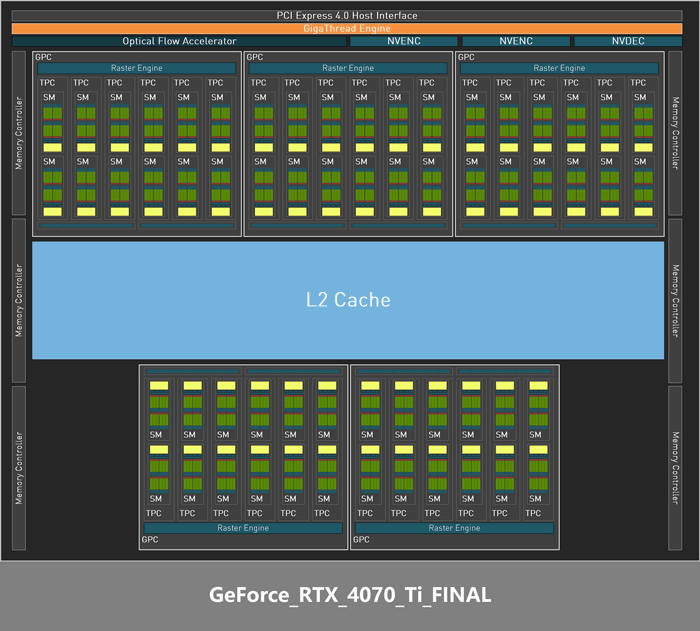
一个完整规格的AD104核心包括了5个GPC (图形处理集群)、30 个TPC (纹理处理集群)、60 个SM (流式多处理器) 、一个带有6个32Bit共256 Bit显存位宽的显存控制器 ,以及四个NVENC和两个NVDEC。
从NVIDIA官方给出来的GPU架构图来看,NVIDIA GEFORCE RTX 4070 Ti显卡采用的是较为完整的AD104核心,7680个CUDA核心,192Bit显存位置,只是在视频引擎上进行了一定的削减。这样的纸面数据,相信NVIDIA GEFORCE RTX 4070 Ti会有不错的性能表现。
GIGAGYTE GeForce RTX 4070 Ti GAMING OC 12G


*PS,GIGAGYTE GeForce RTX 4070 Ti GAMING OC 12G,下述简称“RTX 4070 Ti GAMING OC”

RTX 4070 Ti GAMING OC采用与RTX 4090/80 GAMING OC同款的家族式脸谱设计,正面是AORUS系列显卡常用的多彩RGB三环灯,配合上不同的纹路设计有一种赛博朋克的风味。

背部是一整块的金属背板,可以加固显卡,辅助散热。而尾部是镂空的进气格栅位置,可以加快热量的排出,从而增强散热效能。

尾部镂空的设计已经成本高端显卡中标配的设计,结合上顶部的散热排气口能有效的加大风流,降低扰流的形成。

RTX 4070 Ti GAMING OC辅助供电采用的是12VHPWR接口,也就是我们常说的PCIe 5.0 16Pin显卡供电接口,可以满足600W供电的需求。当然啦,RTX 4070 Ti GAMING OC最大TDP值就是340W,配上12VHPWR接口可以说是大车拉小马了;同时大家不用担心供电接口用不上的问题,显卡附送了一条带上NVIDIA认证的2*8Pin TO 12VHPWR转换线,方便玩家们使用。

接口方面,显卡配合的是三个DP1.4接口与一个HDMI2.1接口,可可以实现3+1联屏输出。

对了,此款显卡带有两个不同的BIOS,一个是OC MODE,另外一个是SILENT MODE,大家可以根据不同的需求。那这两个BIOS之前有什么区别呢?首先频率上,此两个BIOS是没区别的,这个我们可以在GPU-Z上查看到。

其次BIOS之前最大的区别在于风扇转速策略上的不同,从GPUMON软件上可看到,OC MODE BIOS下,49度以下停转风扇,50度风扇转速最高1500rpm,86度风扇转速最高3000rpm。

而SILENT MODE BIOS下,59.9度以下停转风扇,60度风扇转速最高1300rpm,87度风扇转速最高2350rpm。SILENT MODE在停转温度与风扇转速上都要比OC MODE低,有着更好的静音效果。
GIGAGYTE GeForce RTX 4070 Ti GAMING OC 12G,拆解

RTX 4070 Ti GAMING OC显卡PCB采用了较为紧凑式的高集成度PCB设计,左侧是主要是供电模块,而其余了供电则是顶部与右下位置。

由于PCB正面的集成度较高,所以背部反而显得较为简洁一些,主要是一些供电的PWM控制芯片和滤波用的MLCC。

中间的C位永远都是GPU的位置,AD104核心和6颗镁光GDDR6X显存颗粒

用料上来看都很GIGABYTE,就算是GAMING OC定位的显卡都是堆满料的,每相供电都配上固态电容、R15封闭电感,以及DrMos芯片。

两颗BIOS芯片,一个是GPU左侧,一个是GPU顶部

12VHPWR供电的接口,,以及保险电路

主要控制器是来自UPI的uP9512R,目测大部分的RTX 4070 Ti显卡均采用此款高效能的控制芯片。

DrMos芯片采用的是Vishay出品的SIC653A,最大可持续输出电路达到了50A。

这次RTX 4070 Ti GAMING OC显卡采用了是2.5槽的设计,所以你同样会看到较大的WINDFORCE散热系统。此款显卡上的WINDFORCE散热系统采用的是两段式的设计,左侧是GPU的主散热模块,右侧是大面积的散热鳍片。

比较夸张的是,RTX 4070 Ti GAMING OC显卡底部并非采用纯铜板,而是一个定制的均热板。GPU位置加高设计与核心更为紧密的结合上,而VRAM与显存位置均配上的高系数导热垫,辅助不同模块的散热。尤其是显存温度被压得死死的,大家不用担心GDDR6X颗粒会出现高温现象。

多条复合式的散热管

其中6条直接贯穿整个散热模块

RGB 幻彩光轮

WINDFORCE散热系统口碑最好的就是风扇,噪音低效能高,每个风扇的旋转方向与相邻风扇不同,减少扰流并增加气压。
GIGAGYTE GeForce RTX 4070 Ti GAMING OC 12G,RGB灯效


RGB 幻彩光轮灯效,若是想灯效一直常亮,那么你得把风扇启停技术给关掉,这样灯效常在。

GIGABYTE LOGO,可以与RGB 幻彩光轮联动一起打造个性化的灯效。


这里我们实时看到显卡的状态,并加以解锁更高的温度限制,电压限制,以及实现更高的核心频率。当然若你的动手能力有限,那么可以利用OC SCANNER来进行AI超频,软件会对GPU核心进行一系列的测试,从而得到一个更高且稳定的频率。


当然啦,我们这里仅是介绍一下不同的显卡灯效,肩上的LOGO可以与RGB 幻彩光轮进行联动灯效的控制,技嘉这里给出了较多的预设灯效,大家也可以对灯效亮度与速度进行不同的设定,从而打造个性化的RGB灯效。
测试平台介绍:


而配合上旗舰级的处理器,我们拿来的四条Kingston FURY Renegade DDR5 RGB内存,并手动降频运行在DDR5-6000 C32,Gear 2模式下,这样可以确保平台有着更佳性能的同时也有着更高的稳定性。

显示器方面自然是评测室专用的电竞神器——爱攻&保时捷联名 PD32M 4K144 电竞显示器,当然RTX 4070 Ti显卡是被NVIDIA定义为2K高刷的游戏显卡,之后我们也会单独拿到高刷显示器进行单项测试。

同样的在测试前,我们得先确保一下系统配置是否正确。因为前两次RTX 4090、RTX 4080首发时我们测试中就知道,需要在系统和BIOS中进行一定的配置才能开启上DLSS3功能。同时NVIDIA的技术指导文档中已经说到,想要开启DLSS3功能,需要几个步骤:
将硬件加速的 GPU 调度设置为开启
以全屏模式运行游戏以获得最佳性能和最低延迟。
请确保在 NVIDIA 控制面板中将显示器设置为最大刷新率。
建议使用 G-SYNC Ultimate 显示器进行最佳体验评估。
在主板的 SBIOS 中开启 Resizable BAR。
理论性能测试

理论性能方面这里我们区分出来两部分,DLSS2部分的测试由于8K分辨率比例太高,所以我们就没对比做性能比例。
从结果来看,RTX 4070 Ti GAMING OC显卡与RTX 3090 Ti两者的性能比例同样是152%,可以说更高TDP设定的非公RTX 4070 Ti GAMING OC显卡理论性能上已经和旧旗舰RTX 3090 Ti基本一致的。同时你会发现,当开启DLSS技术后,RTX 4070 Ti GAMING OC显卡性能进一步的提升,若上开启DLSS3技术后相信RTX 4070 Ti基本是大幅度的依靠于上代旗舰显卡。
AIDA64 GPGPU测试

GPGPU理论性能测试方面,很好的表明了这一代的ADA架构的三款RTX 40系列显卡在算力上有着较为出色的性能表现,尤其是单精度和双精度浮点运算上,提升幅度是最大的。相比RTX 3090 Ti显卡,RTX 4070 Ti显卡整体的GPGPU算力表现同样要强不少,6K出头的显卡能实现上代旗舰显卡(1W5)的性能表现,着实不错。
创作者能力测试:
视频与平面内容创作方面这次我们测试得比较多,包括了PCMark 10与PugetBench三个大项,其中PugetBench其实把PS|PR|LR|AE|达芬奇这五款较为常见的软件都测试了篇。ADOBE软件使用的是最新的ADOBE 2023版本,而达芬奇是NVIDIA提供的AV1特殊版本。

首先我们来看看PCMARK10 Extended项目上,各显卡的性能表现如何,由于是同一平台,只是更换了不同的显卡进行测试,所以看到对显卡依赖程度较为的【游戏】子项上不同定位的显卡有着较大的差距。当然在【数位内容创作】与【生产力】子项上同样会有小幅度的不同性能差距,总的来说,RTX 4070 Ti GAMING OC显卡在PCMARK10 Extended项目上领先RTX 3090 Ti一些,同时的确比RTX 3070 Ti好不少。
而来到UL Procyon与PugetBench测试中,可看到RTX 3090 Ti还是老当益壮,主要是显存带宽和容量上比RTX 4070 Ti高不少,而且ADOBE全有桶对更成熟的Ampere架构RTX 3090 Ti优化更好一些,所以RTX 3090 Ti内容创作表现的确会比RTX 4070 Ti好。
当然随着ADOBE全有桶、达芬奇,以及是剪映等这些软件的不断优化,相信在ADA架构在这些项目上的优势会被逐步加大,尤其是RTX 40系列显卡还支持了AV1视频格式的编码与解码,这些RTX 30系列都是不具备的。
专业设计领域

专业设计领域的测试项目同样是RTX 40系列显卡的优势所在,你可看到RTX 4070 Ti GAMING OC显卡的专业内容创作能力已经比上代旗舰RTX 4090 Ti强9%了,更不用说比RTX 3070 Ti强出62%了。
AV1能力测试:

刚才我们已经说了RTX 40系列显卡由于是采用了双编码器NVENC,能够支持最新的AV1视频格式的编码解码,那么我们同样使用NVIDIA提供的支持AV1格式的达芬奇软件进行测试。
由于RTX 30系列显卡是不支持AV1的,所以我们这里同样测试的H.265视频的输出,从结果来看,H.265 4K分辨率的视频其实大家都相差不多,也就那么几秒。但若是H.265 4K分辨率的视频下,那他们的差距就真的大的,RTX 4070 Ti显卡导出时间为47秒,虽然比两位老大都要多2秒的样子,但是比RTX 3090 Ti显卡的115秒是真的快多了。而且经过我们多次的测试,AV1格式的视频有着视频的质量高、容量占用低的优势,因此各大视频平台才会主推这样的开源视频格式。
既然我们已经利用达芬奇进行AV1测试,那么我们顺道测试一下RTX 40系列显卡的创作软件上的AI能力。我们测试的项目是AI ACCELERATED MAGIC MASK,利用GFE软件录屏进行AI渲染时间的记录,从结果来看,又是RTX 40系列显卡的优势项目,RTX 4070 Ti相比RTX 3090 T渲染时间缩短了5s,看着不多,但当项目难度更大,更复杂的情况下,渲染优势就会被逐步的拉开。
游戏性能测试:

DLSS3性能测试:
那若是在DLSS3模式下,RTX 4070Ti会有着如何表现呢?我们先来看一下3DMARK中的DLSS理论性能测试,RTX 30系列显卡同样运行在DLSS2模式下,而RTX 40系列显卡运行在DLSS3模式下。

RTX 4070 Ti在DLSS3模式下有着较大幅度的性能提升,大家可看到关闭DLSS下,其性能是比不上RTX 3090 Ti的,但是当开启DLSS3下帧数就大幅领先,ADA架构与DLSS3带来的提升着实的厉害得很。
那你们以为只会是3DMARK的理论性能方面会有所提升吗?你错了,我们在十款支持DLSS3的游戏中,通过开启帧生成功能来实现DLSS2与DLSS模式下的帧数变化,同时利用最新版本的FrameView软件进行帧数记录。

结果表明,1440p分辨率下的RTX 4070 Ti GAMING OC显卡如有神助,DLSS3的帧数生成技术为我们带来了全新的篇章,RTX 4070 Ti GAMING OC显卡有着完全是碾压RTX 3090 Ti显卡的实力。

同时值得注意的是RTX 4070 Ti GAMING OC显卡在多个测试中的功耗表现都相对的低,起码对比RTX 3090 Ti动不动就是380W的显卡来说,那是真低的,200W左右的RTX 4070 Ti能实现超越RTX 3090 Ti的性能着实是让人惊喜。
温度与功耗测试:


无论是满载的核心温度还是满载的显存温度,此款RTX 4070 Ti GAMING OC显卡也是真够低的了,GPU满载温度55.7度,显存满载温度46度,热点满载温度也才62.8度,这温度表现已经比许多的非公版显卡要强多了。同时其风扇转速也才1700rpm左右,实现了高效能散热低噪音的表现,这都是得益于技嘉独立的WINDFORCE散热系统。
超频能力测试:

在测试RTX 4070 Ti显卡的超频之前,我们先看一下默认RTX 4070 Ti GAMING OC显卡跑3DMARK的水平怎么样,在Time Spy得分为23257,显卡在40s时显卡的运行频率是2850MHz。

利用技嘉智能管理解锁更高的温度、功耗,以及电压值,并把风扇转速调整到全速之后,在Time Spy得分为24228,显卡在40s时显卡的运行频率是3045MHz,并通过了TIME SPY的稳定性测试。

稳定性测试中的显卡功耗已经达到了303W,不过显卡核心温度最高才54.9度,是真的低的。

同平台的情况下,我们最终可以把RTX 4070 Ti GAMING OC显卡核心频率+220MHz,显存频率+1500MHz的操作,最终通过测试得分为25093,性能比默认频率提升3.57%。当然啦,这是由于显卡TDP已经撞墙上了,想有更高频率,要么技嘉给出来更高的TDP版本BIOS,要么就是更换更高也阶的非公RTX 4070 Ti,例如大雕RTX 4070 Ti。
总结:

2.技嘉RTX 4070 Ti GAMING OC显卡性能强到什么水平?直接把上代旗舰RTX 3090 Ti给挑下马了,性能在DLSS技术在加持下完全碾压上代旗舰。那么年底预算足够的情况下,等等党真的胜利了,笔者认为旧的RTX 30系列显卡真的不用买,直接来一块RTX 4070 Ti显卡足够了,游戏、内容创作、专业设计全都能满足。

3.技嘉RTX 4070 Ti GAMING OC显卡的WINDFORCE散热太强了,GPU满载也就54.9度,我们完全可以直接使用SILENT MODE来使用,完全不用担心显卡的散热问题。也正因此,此款技嘉RTX 4070 Ti GAMING OC显卡十分适用对环境噪音要求较高的用户,59度以下直接不开风扇,这个实在是爽。

目前此款显卡已经正式在各大电商平台,以及渠道商开卖,有兴趣的玩家可以关注一下。
技术回顾:Ada Lovelace架构优势
Turing、Ampere上两代架构核心均以人物来命名,前者是计算机科学之父——艾伦·麦席森·图灵;后者则是“电学中的牛顿”——安德烈·玛丽·安培,电流的国际单位安培就是以其姓氏命名。那Ada Lovelace定非凡人,度娘一下果然,这是 人称“数字女王”的阿达·洛芙莱斯,编写了历史上首款电脑程序,是被世界公认的第一位计算机程序员,果真是一代比一代还要更牛。PS:她的父亲是《唐璜》的作者,诗人拜伦喔。

全新的SM流式多处理器


过去的Turing架构INT32 计算单元与FP32数量是一致的,而两者相加才组成了64个CUDA核心。但是Ampere架构开始,左侧的计算单元实现了FP32+INT32的计算单元并发执行,也就是说CUDA核心数量翻倍到了128个。
再来看看Ada Lovelace架构的SM,FP32/INT32的计算单元组合,同样实现了每个SM内含128个CUDA的设计,看似提升不大,但是当你了解到GeForce RTX 4090拥有128个SM,16384个CUDA核心,那你也就应该明白达82.6 TFLOPS的着色器能力是如何实现的了,比上一代的RTX 3090 Ti显卡的40 TFLOPS,还真是提升了两倍有多。

另外缓存方面Ada Lovelace架构也进行了大规格的提升,首先每个SM单元中单独配上了128 KB的缓存,这样RTX 4090/RTX4080显卡中就实现了更大的L1/共享内存以及更大的L2缓存,因此Ada Lovelace架构核心对显存位宽的依赖性并不高。
技术讲解:第三代 RT Cores与第四代 Tensor Cores

以为刚才的CUDA数量与超大L2缓存就已经很猛了,实现上Ada Lovelace架构最大的提升还是在第三代 RT Cores与第四代 Tensor Cores身上。
第三代 RT Cores

RT Cores用于光线追踪加速,第三代 RT Cores 的有效光线追踪计算能力达到 191 TFLOPS,是上一代产品 2.8 倍。

在Ampere架构中,第二代RT Cores支持边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersection testing),用于加速BVH遍历和执行射线三角交叉测试计算,虽然光线追踪处理能力已经比初代的Turing架构核心更高效,但是随着环境和物体的几何复杂性持续增加,传统的处理方式很难再以更高效率、正确反应出的现实世界中的光线,尤其是光的运动准确性。
所以在第三代 RT Cores增加了两个重要硬件单元:Opacity Micromap Engine与Displaced Micro-Meshes Engine引擎。Opacity Micromap Engine,主要是用于alpha通道的加速,可以将 alpha 测试几何体的光线追踪速度提高2倍。

在传统光栅渲染中,开发人员使用一些 Alpha 通道的素材来实现更高效的画面渲染,例如 Alpha 通道的叶子或火焰等复杂形状的物体。但在光线追踪时代,这传统的做法会为光线追踪带为不少无效的计算,例如运动性的光线多次通过一块叶子,光线每击中一次叶子,都会调用一次着色器来确定如何处理相交,这时就会做成严重的执行成本与时间等待成本。

而Opacity Micromap Engine用于直接解析具有非不透明度光线交集的不透明度状态
三角形。根据Alpha 通道的不透明,透明与未知等三个不同的块状态进行处理:透明则直接忽略继续找下一个,不透明块则记录并告之命中,而未知的则交给着色器来确定如何处理,这样GPU很大部分都不需要进行着色器的调试处理,能够实现更为高效的性能。
Displaced Micro-Meshes Engine

如果说Opacity Micromap Engine加速的是面处理,那么Displaced Micro-Meshes Engine就是几何曲面细节的加速器。如上图所示,在Ada Lovelace架构中,通过1个基底三角形+位移地图,就可以创建出一个高度详细的几何网格,所需要资源占用比二代RT Cores更低,效率也更高。

通过NVIDIA给出的创建14:1珊瑚蟹例子来说事,这里我们需要需要1.7万个微网格、160万个微三角形,在Ada Lovelace架构中BVH创建速度可加快7.6倍,存储空间缩小8.1倍。Displaced Micro-Meshes Engine起到了关键性的作用,其将一个几何物体根据不同细节分成密度不一的微网络处理,红色密度超高,细节处理越为复杂 。相应的低密度微网络区域则可以释放更多的资源与存储空间,这样Displaced Micro-Meshes Engine就可以帮助BVH加速过程,减少构建时间和存储成本。

同时Ada Lovelace架构SM中新增了着色器执行重排序(Shader Execution Reordering,SER),这是由于光线追踪不再只有强光或者阴影渲染处理,未来将会更多的是在光线的运动性,这样光线就会变得越来越复杂,想要第三代 RT Cores与第四代 Tensor Cores有着更高的执行效率,那就得为他们来安排一位管家。而着色器执行重排序(SER)就是为了能够即时重新安排着色器负载来提高执行效率,为光线追踪提供2倍的加速,也能更好地利用 GPU 资源。不过目前仍未有实例,想实现这个功能,还得游戏与开发工具的支持才行。
第四代 Tensor Cores

Tensor Cores是专门为执行张量/矩阵运算而设计的专用执行单元,这些运算是深度学习中使用的核心计算功能。第四代 Tensor Cores 新增 FP8 引擎,具有高达 1.32 petaflops 的张量处理性能,超过上一代 的 5 倍。
技术讲解:DLSS3
或者说第四代 Tensor Cores太硬核你不会知道是啥?提升意义在哪?但是Tensor Cores最经典的应用DLSS你肯定会知道,这一次Ada Lovelace架构支持NVIDIA最新的DLSS3技术。
之前我们也聊过DLSS技术,其设计之初是为了弥补光线追踪技术后的性能损失,具体的表现为开启光线追踪技术后游戏帧数大幅度的下降,甚至很难保证游戏流畅的运行。于是DLSS使用低分辨率内容作为输入并运用AI技术输出高分辨率帧,从而提升光线追踪的性能。

在DLSS3中包含了三项技术:DLSS 帧生成、DLSS 超分辨率(也称为 DLSS 2)和 NVIDIA Reflex。你可以理解为DLSS3是在DLSS2的基础上,新增了DLSS 帧生成技术;而后两技术中,DLSS 超分辨率只需要GeForce RTX显卡都能使用上,NVIDIA Reflex则是GeForce 900 系列以后的显卡都用使用上。

想实现DLSS 帧生成可不简单,这需要配合上Ada Lovelace架构的GeForce RTX 40系列显卡才行。DLSS 帧生成技术原理是:利用 AI 技术生成更多帧,以此提升性能。DLSS 会借助 GeForce RTX 40 系列 GPU 所搭载的全新光流加速器分析连续帧和运动数据,进而创建其他高质量帧,同时不会影响图像质量和响应速度。

从Ampere架构开始,NVIDIA显卡就已经支持了光流加速器,而Ada Lovelace架构的光流加速器升级到了第二代,其提供了高达300 TeraOPS (TOPS) ,比安培架构的初代光流加速器(Optical Flow Acceleration,OFA)快 2 倍以上。为了实现DLSS帧生成,OFA扮演了重要的角色,其配合上新的运行⽮量分析算法在DLSS3技术框架内实现精确和高性能的帧生成能力。

最后由于DLSS 3是建立在DLSS 2基础之上的,游戏开发者可以在已支持DLSS 2或NVIDIA Streamline的现有游戏中快速集成该功能,所以DLSS 3已在游戏生态得到广泛应用,目前已有超过35款游戏和应用即将支持该技术。
阅读小亮点:NVIDIA Reflex
NVIDIA Reflex也是DLSS3其中的一环,它可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。


当GeForce RTX 40 系列显卡和 NVIDIA Reflex搭配上后,直接达到1440p分辨率360 FPS的体验,这着实是性能有点强劲了。

在GTC2022大会时已经透露将会还有4 款 1440p 分辨率的新型 G-SYNC 电竞显示器将要发布,包括采用mini-LED技术的AOC AG274QGM – AGON PRO Mini LED、MSI MEG 271Q Mini LED 和 ViewSonic XG272G-2K Mini LED三款显示器刷新率均为300Hz,而最猛的是ASUS ROG Swift 360 Hz PG27AQN ,刷新率直接来到了360Hz。
技术讲解:双 NVIDIA 编码器(NVENC)

GeForce RTX 40 系列显卡还有一个全新的升级,那就是双编码器NVENC。第八代的NVENC双编码器不仅支持H.264与H.265,还支持开放式视频编码格式 AV1。

而由于AV1是一种免版税的视频编码格式,上游软件厂商与下游戏的配套端都在大力推广此编码格式,我们也会看到越来越多的硬件与软件支持AV1格式,包括剪映专业版、DaVinci Resolve、以及 Adobe Premiere Pro 较为流行的 Voukoder 插件均支持,且均可通过编码预设使用双编码器,这样我们等待视频导出的时间缩短将近一半。

不单是视频制作软件,AV1格式也将会是主播、游戏直播UP主们的新宠儿,在保证画面最高质量的情况下,AV1 编码器可将效率提高 40%,同时显卡的占用也更低。包括OBS Studio一一代软件中也会增加AV1格式的支持。另外我们还能通过 GeForce Experience 和 OBS Studio 录制高达 8K60 的内容,这样我们做游戏录制也会变得更为轻松。

包括我们之后测试时使用的游戏内录视频都是支持AV1格式,同时双编码器NVENC在资源占用和适配上做得越来越好。

