回归模型是我们在处理数据中常用的方法。其中,Lasso模型是一种适用于多重共线性问题,能够在参数估计的同时实现变量的选择的回归方法。
Lasso的完整名称叫最小绝对值收敛和选择算子算法,是一种替代最小二乘法的压缩估计方法。Lasso的基本思想是建立一个L1正则化模型,在模型建立过程中会压缩一些系数和设定一些系数为零,当模型训练完成后,这些权值等于0的参数就可以舍去,从而使模型更为简单,并且有效防止模型过拟合。被广泛用于存在多重共线性数据的拟合和变量选择。
LASSO回归复杂度调整的程度由参数 λ 来控制,λ 越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。 LASSO回归与岭回归(Ridge)同属于一个被称为Elastic Net的广义线性模型家族。 这一家族的模型除了相同作用的参数 λ 之外,还有另一个参数 α 来控制应对高相关性数据时模型的性状。 LASSO回归 α=1,Ridge回归 α=0,一般Elastic Net模型 0<α<1。
欠拟合与过拟合
案例(线性回归)
从左往右依次是欠拟合,拟合效果良好和过拟合。

欠拟合:第一张图的模型过于简单,而且损失函数的收敛速度很慢。这就使得优化算法做得再好,我们的模型的泛化性能也会很差,因为模型没有正确认识到数据体现的普遍规律,无法对作出良好的预测。
拟合效果良好:第二张图像大致穿过了样本点。像极了做物理实验时,最后用一条曲线大致地穿过既定的样本点;和第一张图比起来,至少损失值大大下降了。
过拟合:第三张图引入了高次项,对于任意n个点,总能找到n+1次曲线方程将这n个点全部穿过,但是从模型的角度来讲,这显然不是好模型,模型将数据中的全部信息都当做普遍规律,用于样本外的测试情况时可能将一些片面的、只体现于小部分样本的规律误认为是复合总体样本的普遍规律了,这种的模型最终效果也是不好的。
案例介绍
现对一批糖尿病患者进行分析,分别获得了年龄、性别、体重指数、平均压等数据,现使用Lasso回归分析年后疾病进展的测量值和重要影响变量

软件操作
Lasso回归主要用于变量的筛选,做之前要先做线性回归确保自变量存在多重共线性(VIF>5,严格为10),如果数据并没有共线性,依旧建议使用普通线性最小二乘法回归。
 线性回归结果表
线性回归结果表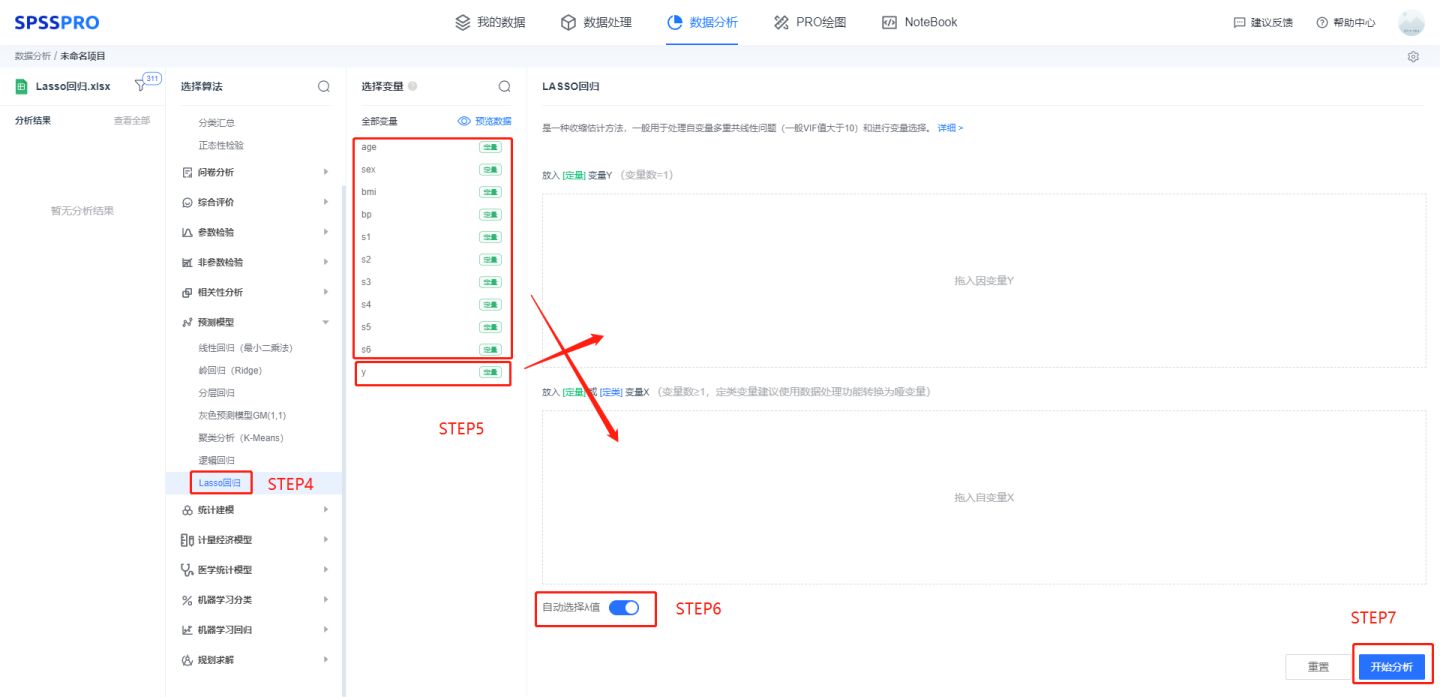
输入:自变量X至少一项或以上的定量变量或二分类定类变量,因变量Y要求为定量变量
结果解读
1)Lasso回归交叉验证图

上图以可视化形式展示了使用交叉验证选择λ值的情况。
纵坐标:模型均方误差
横坐标:λ的对数值
使用交叉验证的方法进行λ值的选择,选择的标准是使得模型均方误差最小,SPSSPRO自动给出了当均方误差最小的λ值=0.02,log(λ)=-3.902。
2)λ与模型回归系数图

随着λ的对数值变化,模型系数也在变化,变为0的时候可以认为被排除出了模型。
3)模型系数表

上表展示了模型系数情况,当模型中标准化变量系数为0时,代表这个变量被排除出模型。
Lasso回归的结果显示:
age、S2两个变量是不重要的,被排除出模型。
4)模型结果图

上图展示了本次模型的原始数据图、模型拟合值、模型预测值。
5)模型结果预测

注意:
一般会先对数据中心标准化,再进行LASSO回归的处理,SPSSPRO在运算时已经进行了标准化,故不需要再进行标准化。
Lasso回归主要用于变量的筛选,如果数据并没有共线性,依旧建议使用普通线性最小二乘法回归。 -LASSO使用L1正则化,岭回归使用L2正则化,L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况

