现在我的笔记全用 Obsidian 管理了,而使用场景中我又要常聚合相关笔记内容进行阅读。之前我有讲解过实践的方法,但似乎还有些不太完善,所以此文是在之前成文的基础上,本人对Obsidian中内容聚合管理的一些思考和改进。
在前面的文章中,我详细介绍了阅读及笔记工作的整体流程,也讲解了从笔记整理到建立TOC的步骤级操作,因此本文不再重复前文的内容,如果你还未阅读,可先参考如下链接,否则可跳至链接后面继续阅读:
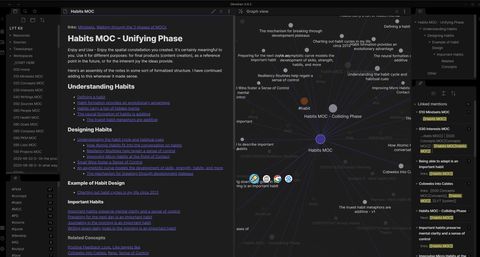
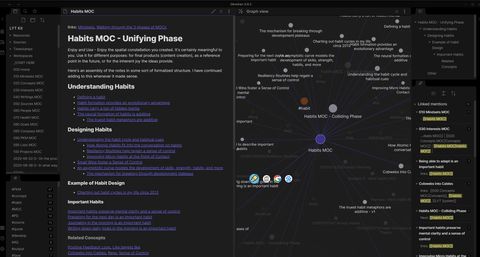
本文从前文内容做了延伸,对前文内容做了进一步思考,解决如:1.如何更好使用多级标签及关键字来引用块粒度级的内容。2.如何结合Obsidian的关系图谱来探索知识并进行思维发散。
说明:本文使用了两个插件: Admonition / Text expand,请自行下载并查阅基础的软件帮助手册,此文不再赘述。
步骤一:
我们之前的链接:Obsidian 笔记整理及TOC索引(二) - 知乎 中使用Text expand语法的一处示例如下,但还有些不足需要改进:
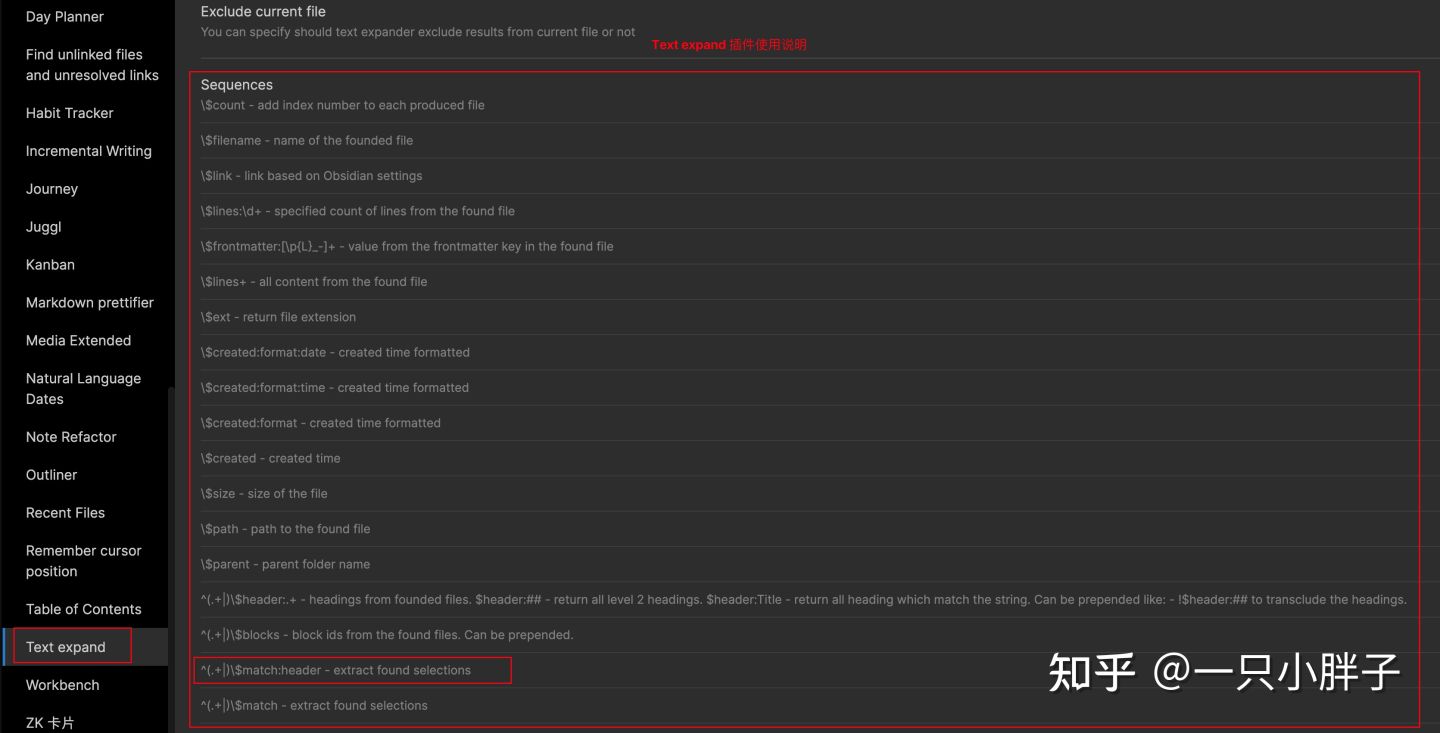 Text expand 插件使用语法
Text expand 插件使用语法
关键字搜索:基本示例写法,引用标题级粒度的内容,更多请参考官方文档:```expander/^(.*)信息流(.*)\n/$header:##!$header:###```
如上,按关键字全文内容匹配,并引入标题内容会带来两个问题:首先搜索出的结果太范,不能精准匹配我们想要的内容,其次会引入同级的其它多级标题下的内容。因此本文改进如下:
标签搜索:用关键字或多标签查询,并用!$match:header来精确匹配标题:```expander /^(.*)#供应链/ !$match:header``````expander tag: #数据分析/巨量千川 !$match:header``````expandertag:程序化投放 OR tag:智能放量 OR tag: #数据分析/巨量千川!$match:header ``` ![[2021-06-22#巨量引擎Marketing API平台介绍]] ![[2021-06-24#平台效果工具类]] ![[2021-07-06#巨量千川数据分析]]
如下图,引用内容使用 Text expand 的查询语法,使用了 !$match:header 精确引用section级别内容。如果你要引用 block 级别内容,可以直接使用 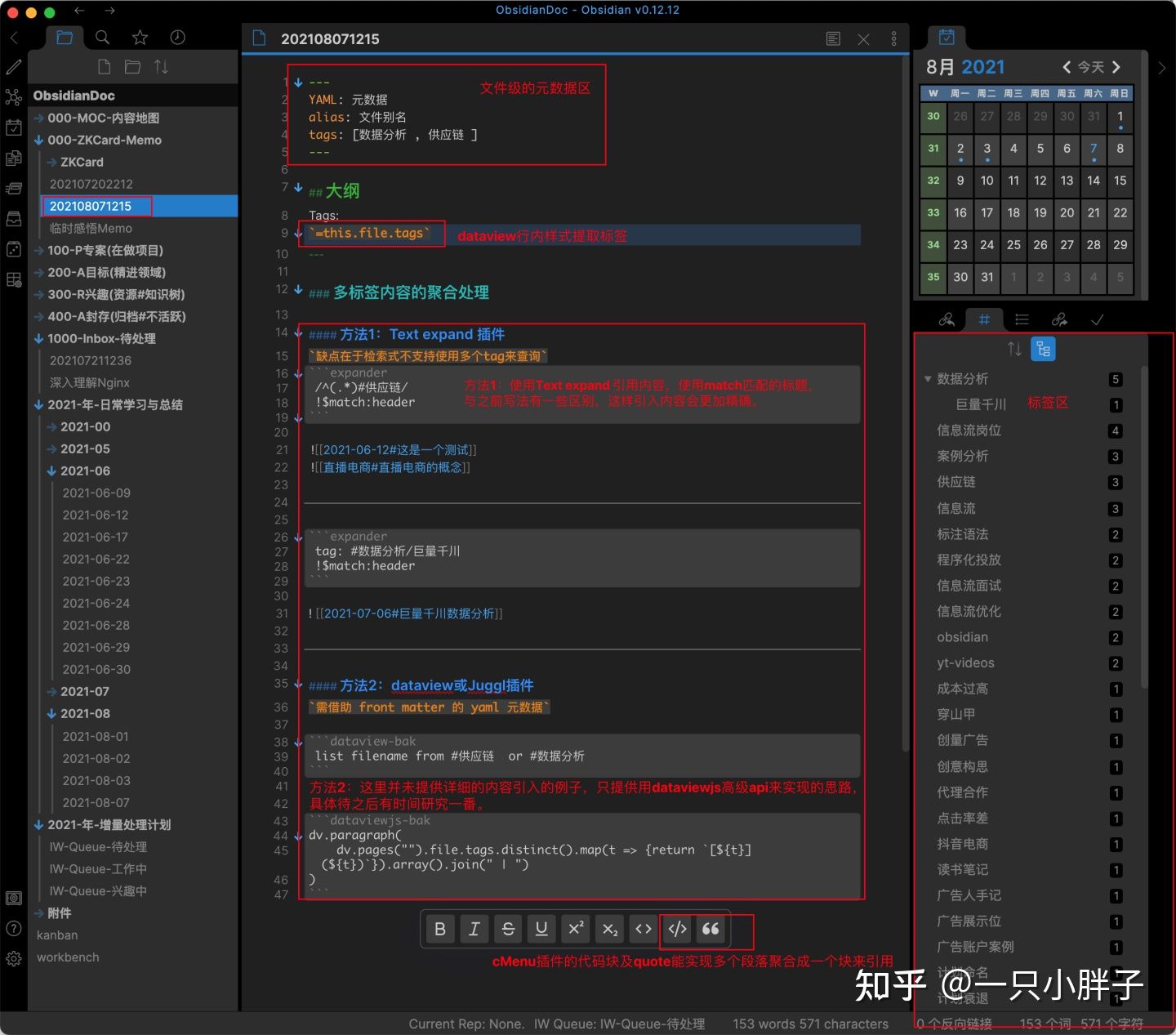 最终笔记内容引用处之写法
最终笔记内容引用处之写法
如下图,被引用的笔记内容区,我们使用大纲标题以及admonition代码块形式来划分笔记内容粒度(当然obsidian的cMenu插件可直接使用quote及code block来划分笔记内容粒度,但体验及功能上没有admonition好,因此此文统一使用了admonition插件),这里要注意的是标签写在admonition代码块中现在是不支持的,而非代码块写法因为对markdown笔记的污染及渲染不稳定,所以我们把标签写在了admonition代码块外面,并放置于大纲标题下方便引用。
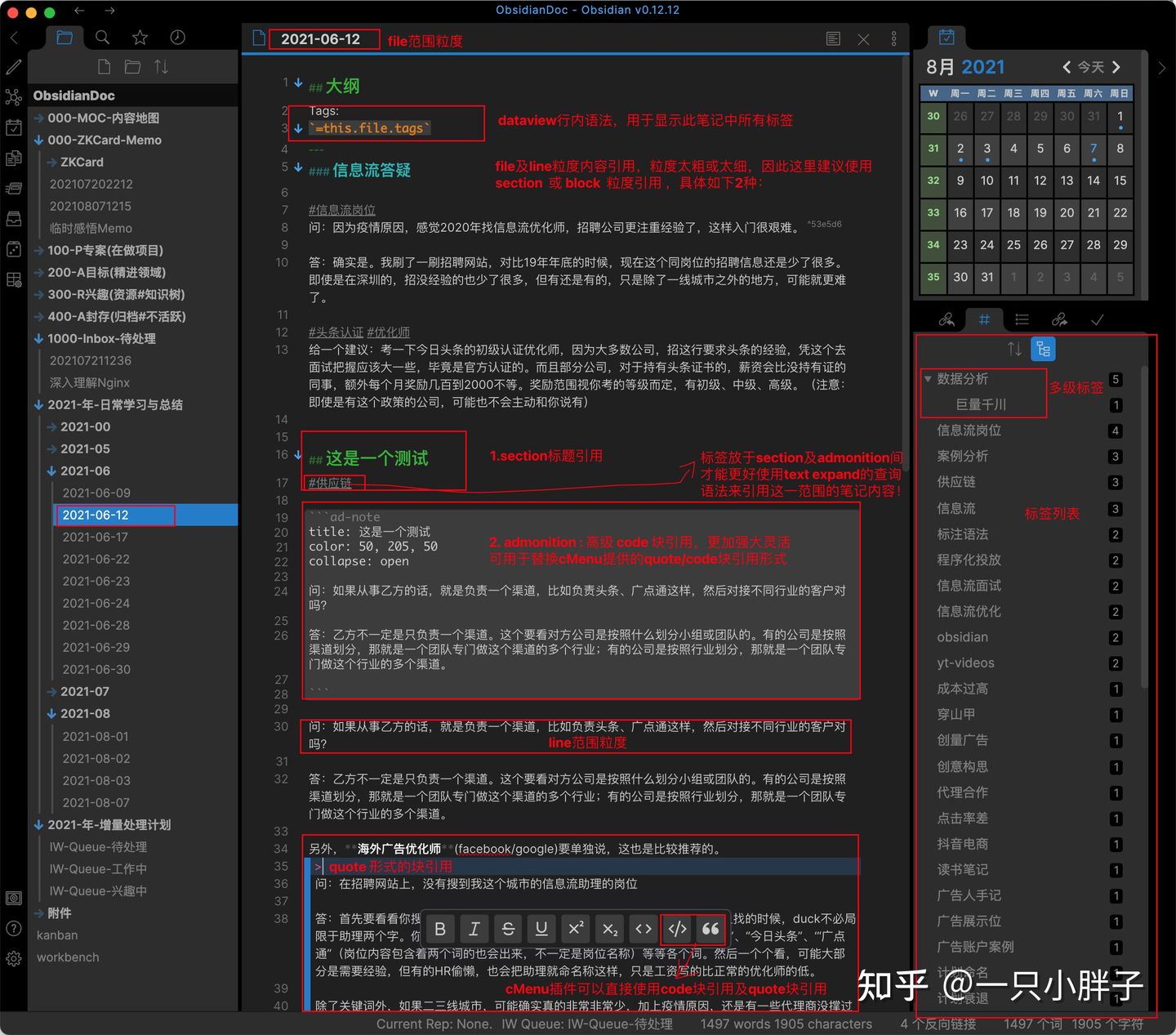 被引用笔记内容之组织结构
被引用笔记内容之组织结构
--2021-09-14 添加如下:内容引用的完善:
在此步骤一开始处,于链接: Obsidian 笔记整理及TOC索引(二)- 知乎 一文中我们在实现内容引用、嵌入等操作时,采用了 query语法查询信息,并在引用这些返回信息的地方,用了引用或嵌入语法来实现,具体在文中 “多条件查询及快速引用、嵌入演示”小节,这是第一种实现内容关联的方式。如链接文中所述,这种操作要自己一个个手写引用,太过繁琐,不利于批量引用文本块内容。
所以在文中后面作了第二种方式的补充,具体在文中"--2021-07-21 添加如下: 参考",我们通过使用Text expand的expander语法来实现。使用多级标签、关键字来查询,并返回多级标题或精确标题信息,但该插件返回信息还是有一些问题的,如只返回了第一个精确匹配项或是返回了同一文档的不相关标题信息,不满足我只想得到标签条件精确匹配到的所有标题。所以这里要看插件作者是否优化一下插件的返回,才能实现类似 flomo软件用标签检索时返回标签对应所有关联内容的效果。
除了如上两种建立块内容关联的方式:第一种纯手打,第二种全自动;我们还可以使用以下插件来实现文本块内容的快速引用或嵌入操作,即第三种半自动方法:
Drag and Drop Blocks 插件或者 Copy Block Link 插件,使用这两个插件我们可以更加快速的对编辑器中的块内容或查询返回的块内容进行引用、嵌入等操作,实现对以上两种方式的有效补充。这两个插件的介绍及官网链接请见(在下文中直接搜索插件标题即可):
Obsidian双链核心即是引用:如文件、标题、块级或借助Admonition实现的跨级引用。通过以上三种引用方案,我们便可对各个笔记,实现不同粒度内容的随意引用、嵌入等关联操作。
步骤二:
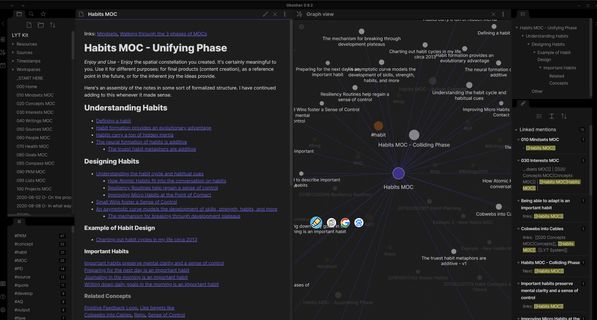
在flomo笔记中,我们会大范围的使用标签来管理内容,在obsidian中我也会比较倾向使用标签或多级标签以及关键字来对笔记内容进行标志,方便我们后期的检索及组织。如下图,我们使用了多个标签来检索内容,我们使用 tag:程序化投放 OR tag:智能放量 条件来查询,最终返回了两个笔记,打开笔记,我们又能通过笔记的关系图发掘出更多的正反链文件及标签。因此其实最终可以对标签相近归类,选取自已常用的标签并进行颜色绑定。
 图一:通过搜索来发现匹配笔记
图一:通过搜索来发现匹配笔记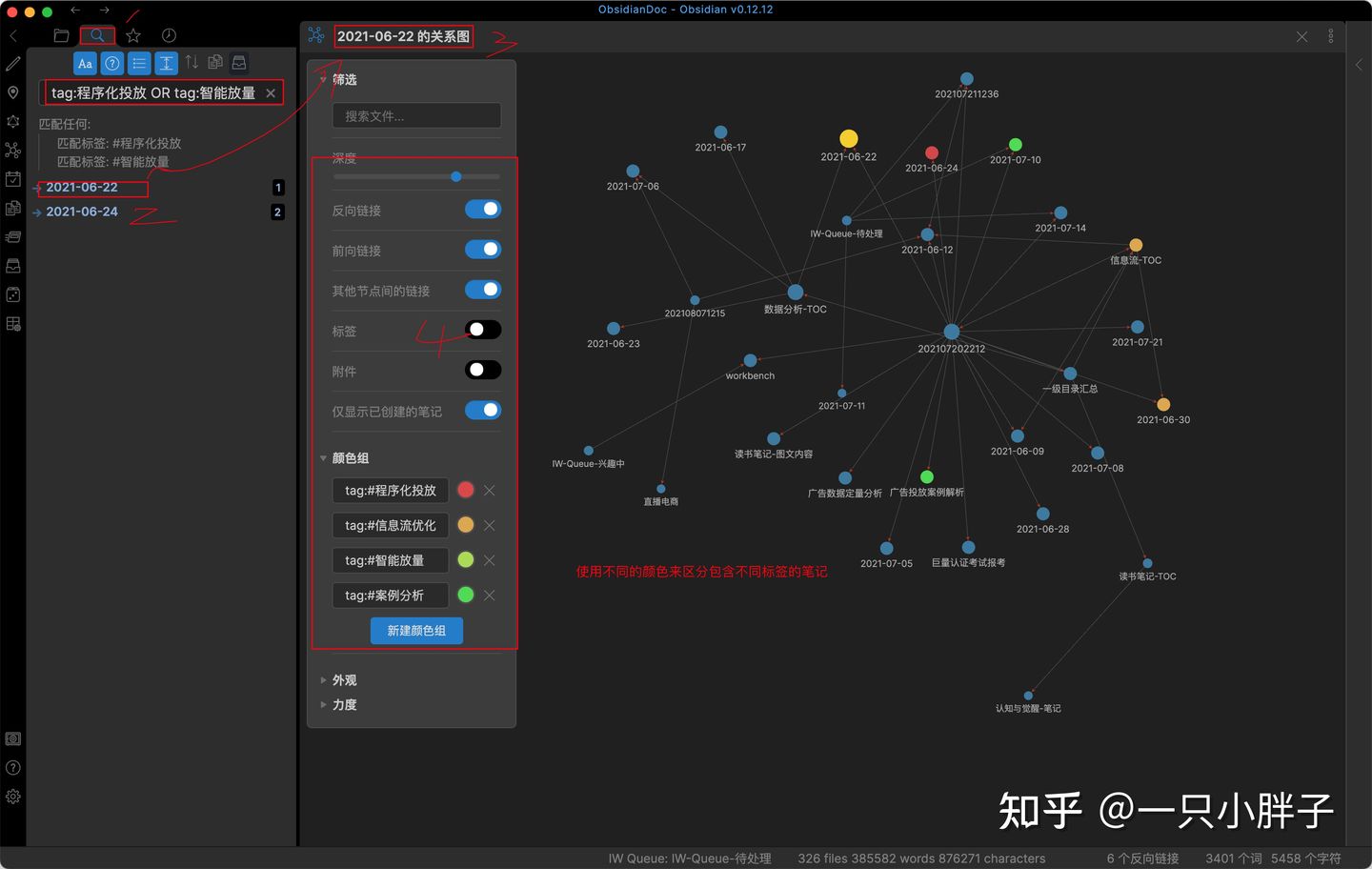 图二:通过标签来区分笔记颜色
图二:通过标签来区分笔记颜色
如果按以上图一、图二所示,基于局部关系图谱的方式,操作不太方便,你还可以在全局图谱中进行更简单的管理 ( 不用在查询框中输入多个条件并设置条件顺序了,同时多条匹配的笔记记录都在全局图谱中可以展示,如上的2021-06-22与2021-06-24笔记 )。
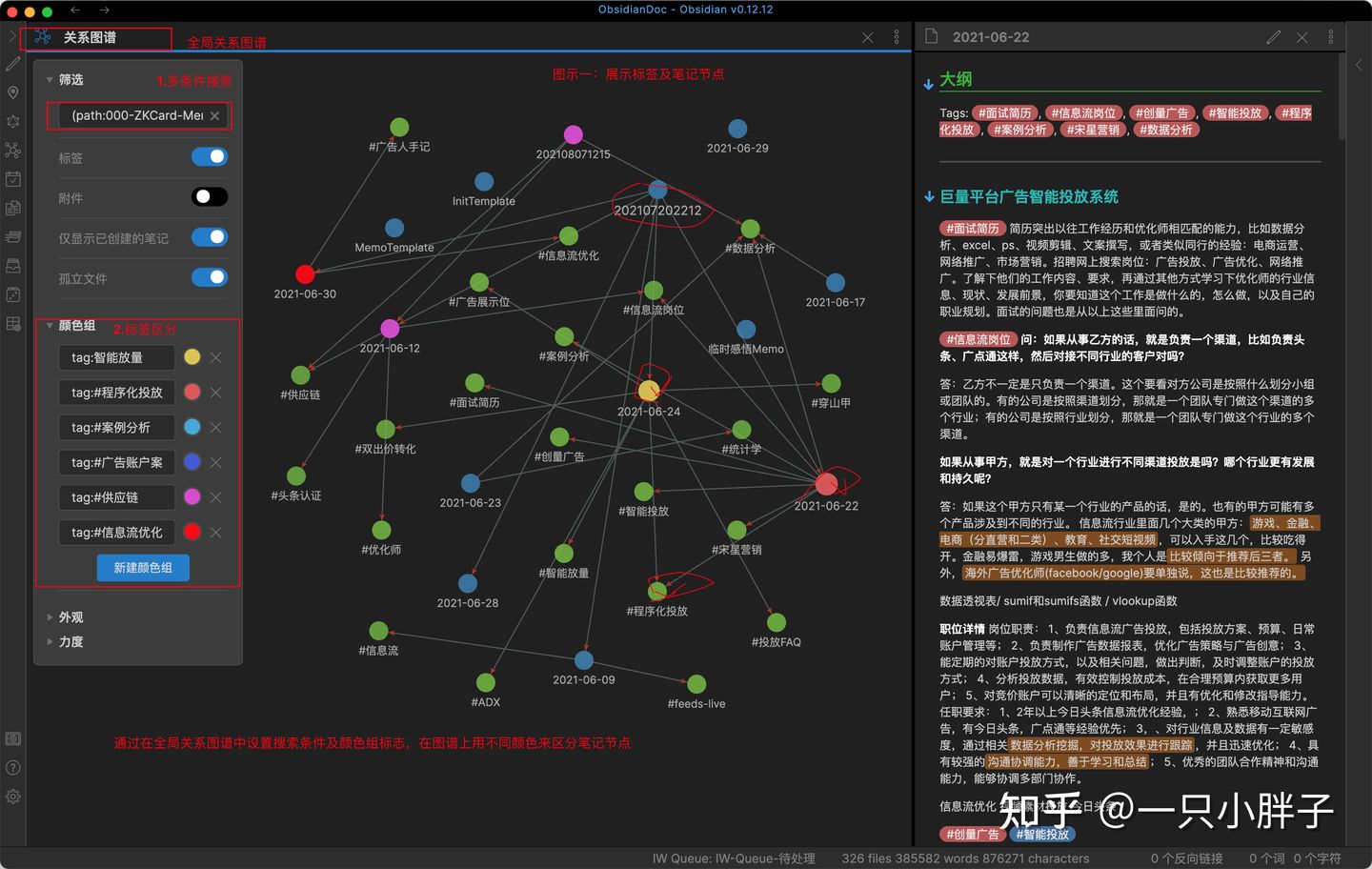 图三:全局图谱中搜索匹配笔记
图三:全局图谱中搜索匹配笔记
通过在全局图谱中设置多标签组合或多条件组合的形式来查询,相比使用标签面板或左上角搜索工具框来检索笔记更加高效和强大。我们可以按优先级或当前业务关注点来拖动全局图谱中颜色组上的查询条件,或重新设置筛选条件,来动态的更新图谱,并随时右键打开颜色标志过的笔记或者对孤立的笔记完善标签,重新组织内容。
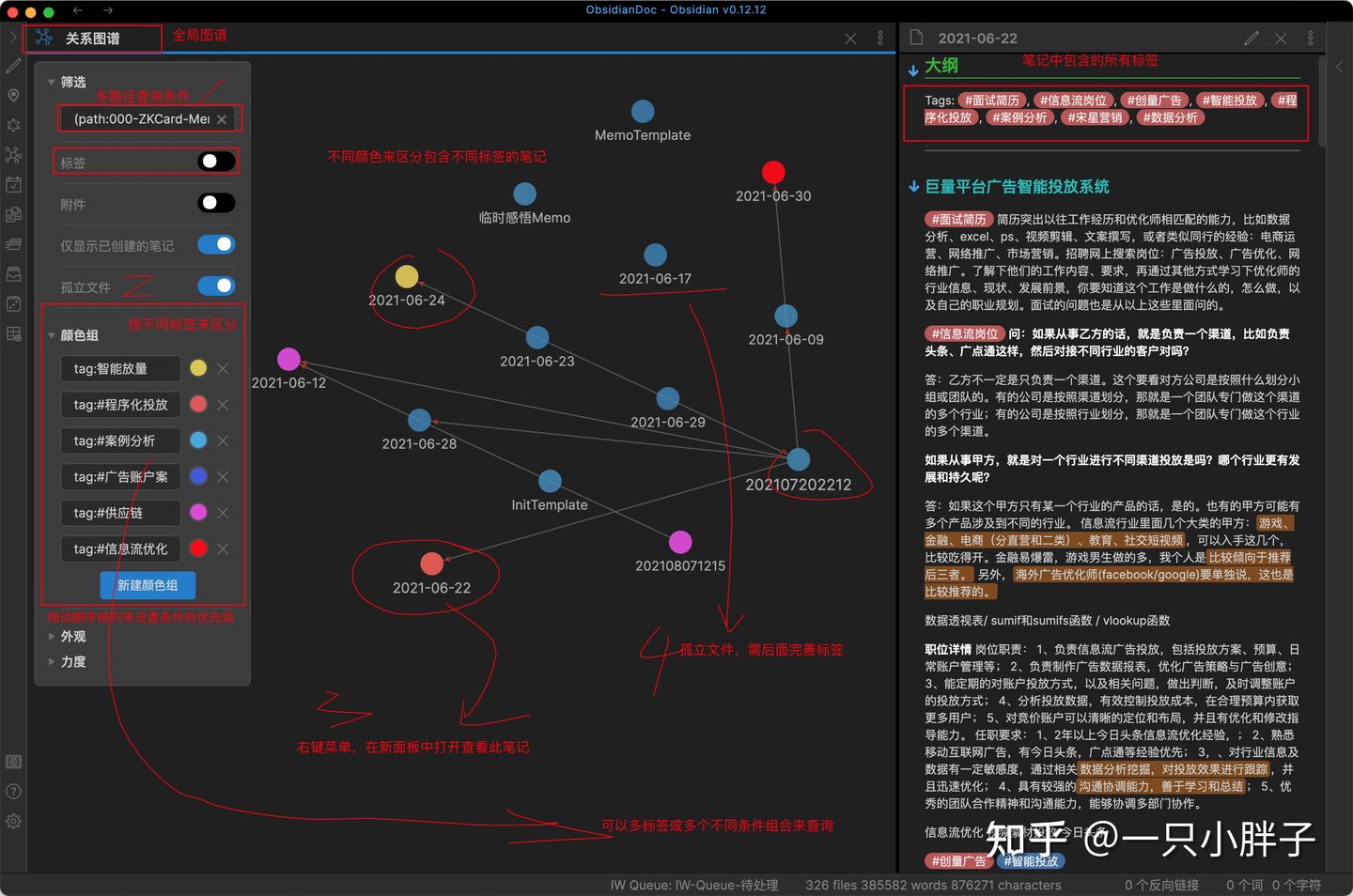 图四:通过标签来区分笔记颜色
图四:通过标签来区分笔记颜色
推荐有用的两款插件
最后,再推荐两款有用的插件,Journey 插件用于发掘两个笔记间的关系,它会将两个笔记间关联的路径找出来,假设我们不知道A->B->C->D四个笔记间有此明确联系,那么当我们输入A文件名及D文件名并点确定后,插件会帮我们发掘出了B->C的中间路径。所以有时在增量写作或特定研究领域,它兴许能给我们一些突然的灵感或启发。
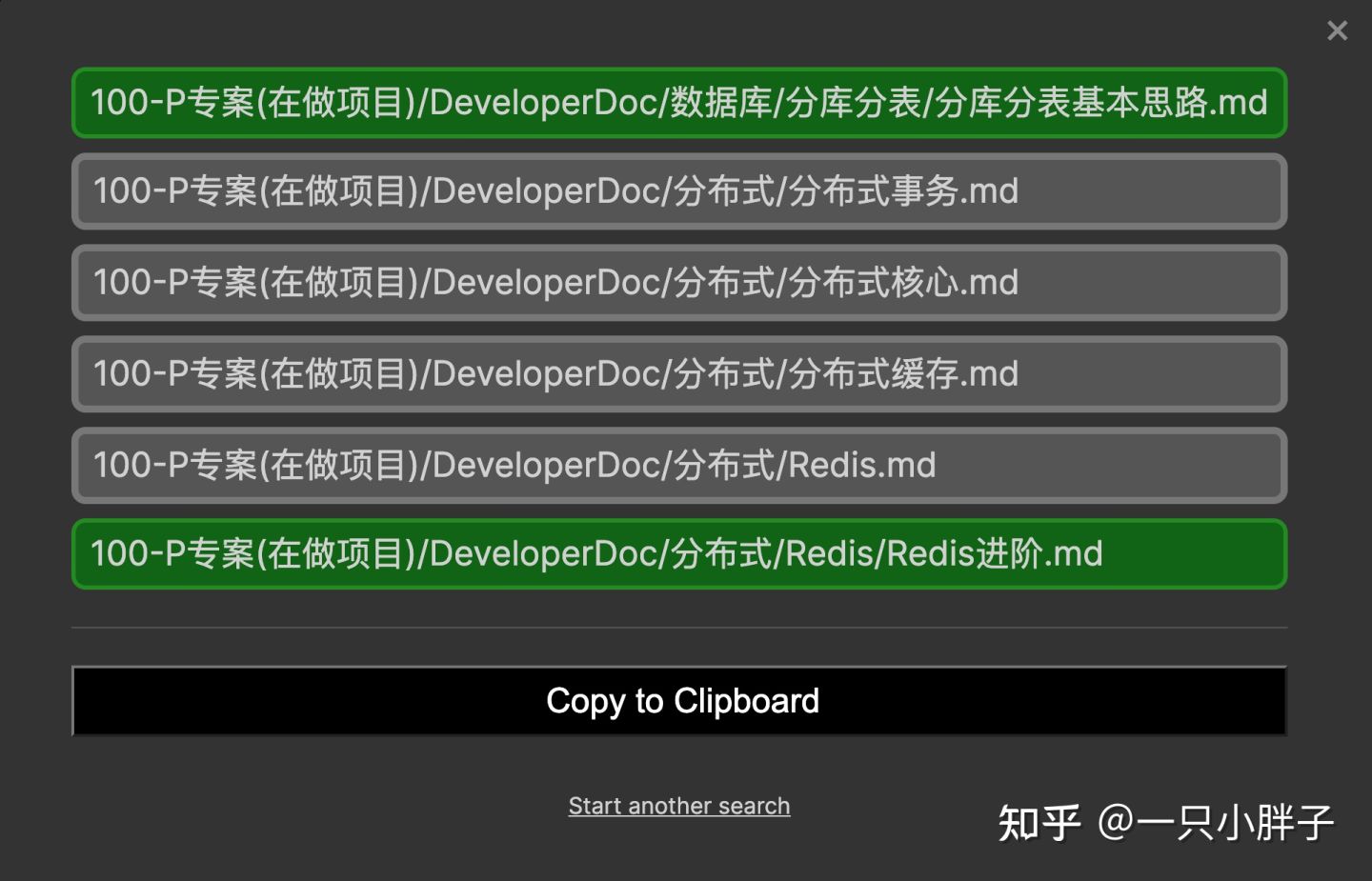 Journey插件的展示
Journey插件的展示
Juggl 是一款Obsidian上的可视化插件,它提供了更多可配置的标签色系,以及按不同结构布局来开展笔记可视化的能力,是对Obsidian自带可视化效果的补充。
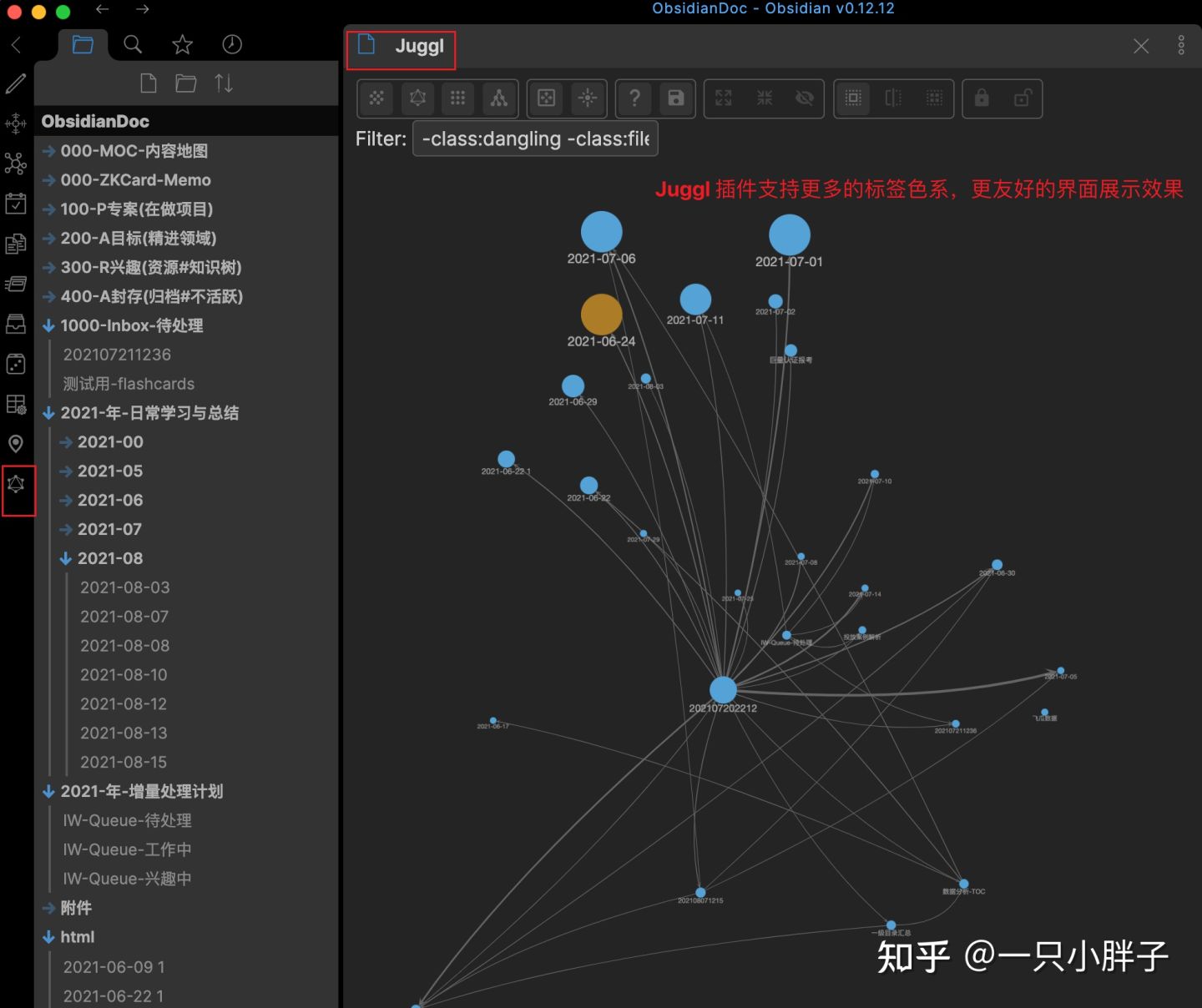 Juggl插件的展示效果
Juggl插件的展示效果
总结:
我们使用标签及关键字来划定笔记内容的引用范围,通过 section标题粒度及块粒度进行内容聚合,并使用全局图谱进行笔记的漫游和思维发散。这里的理念和flomo的理念基本上是一致的。
因此最后放上一张 flomo · 浮墨笔记 (flomoapp.com) 的介绍:
相关链接:

补充链接:

结束:
至此,本文结束.... 欢迎小伙伴们一起探讨和评论!

