本文是对“NewSQL大神黄东旭:从0到1,如何设计一个分布式数据库”讲座的一些理解与笔记,希望对大家有帮助。
Outline
为什么我们需要一个新的分布式数据库
NewSQL主流设计模式及架构(Google Spanner / Amazon Aurora)
TiDB Project的设计与实现
大规模分布式系统测试经验,以TiDB集群测试为例
分布式存储学习路径,经验分享
我们为什么需要一个NewSQL
数据正以前所未有的速度增长
AI/数据挖掘的趋势
分布式系统成为主流
传统的RDDMS已不能满足许多公司的需求
可扩展性
OLTP和OLAP是相互分离的
ETL是一个痛苦的过程...
SQL永远不会消失
NewSQL主流设计模式及架构
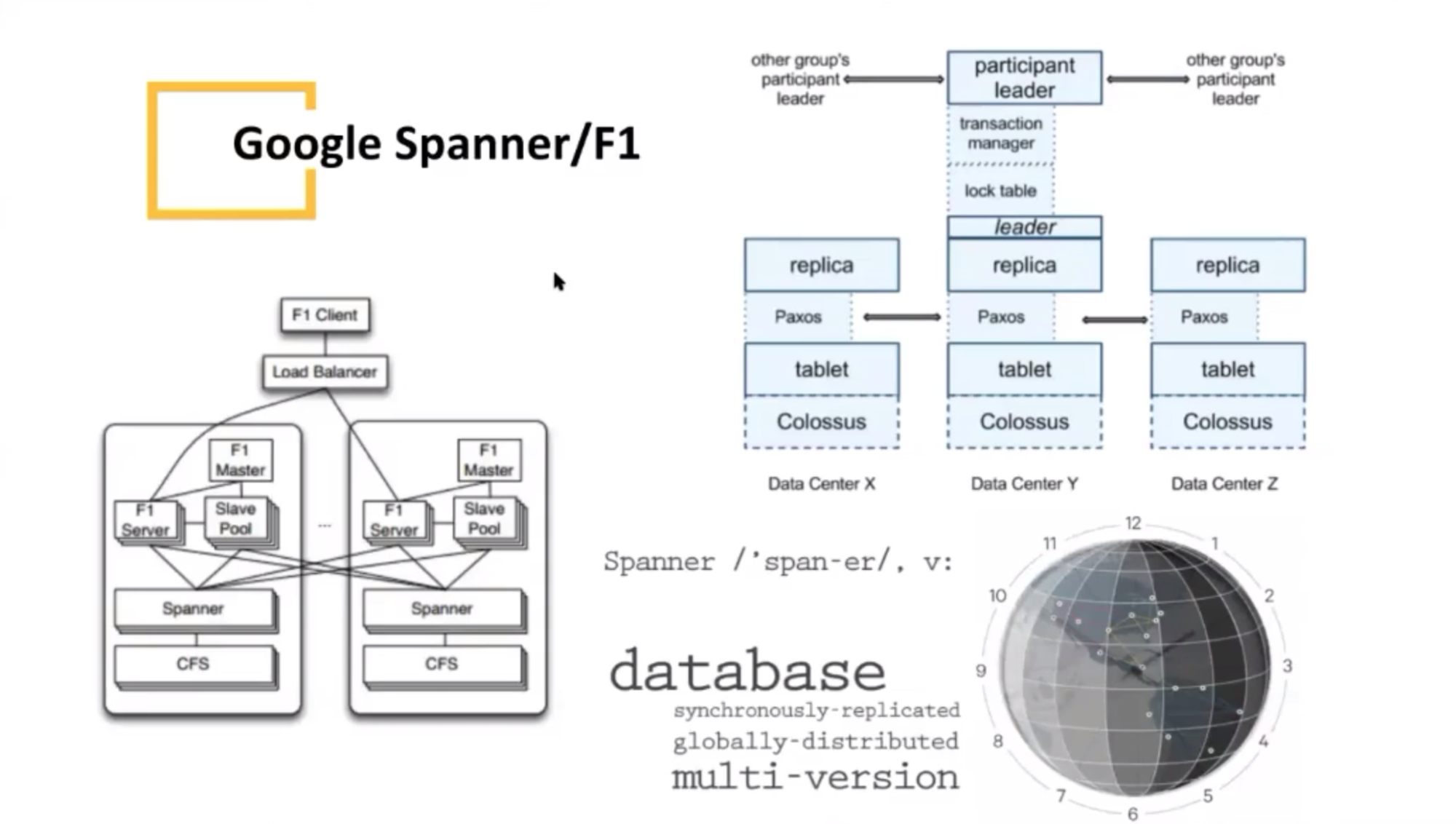
Google Spanner
《Spanner: Google’s Globally-Distributed Database》论文翻译
一个很大的数据库承载
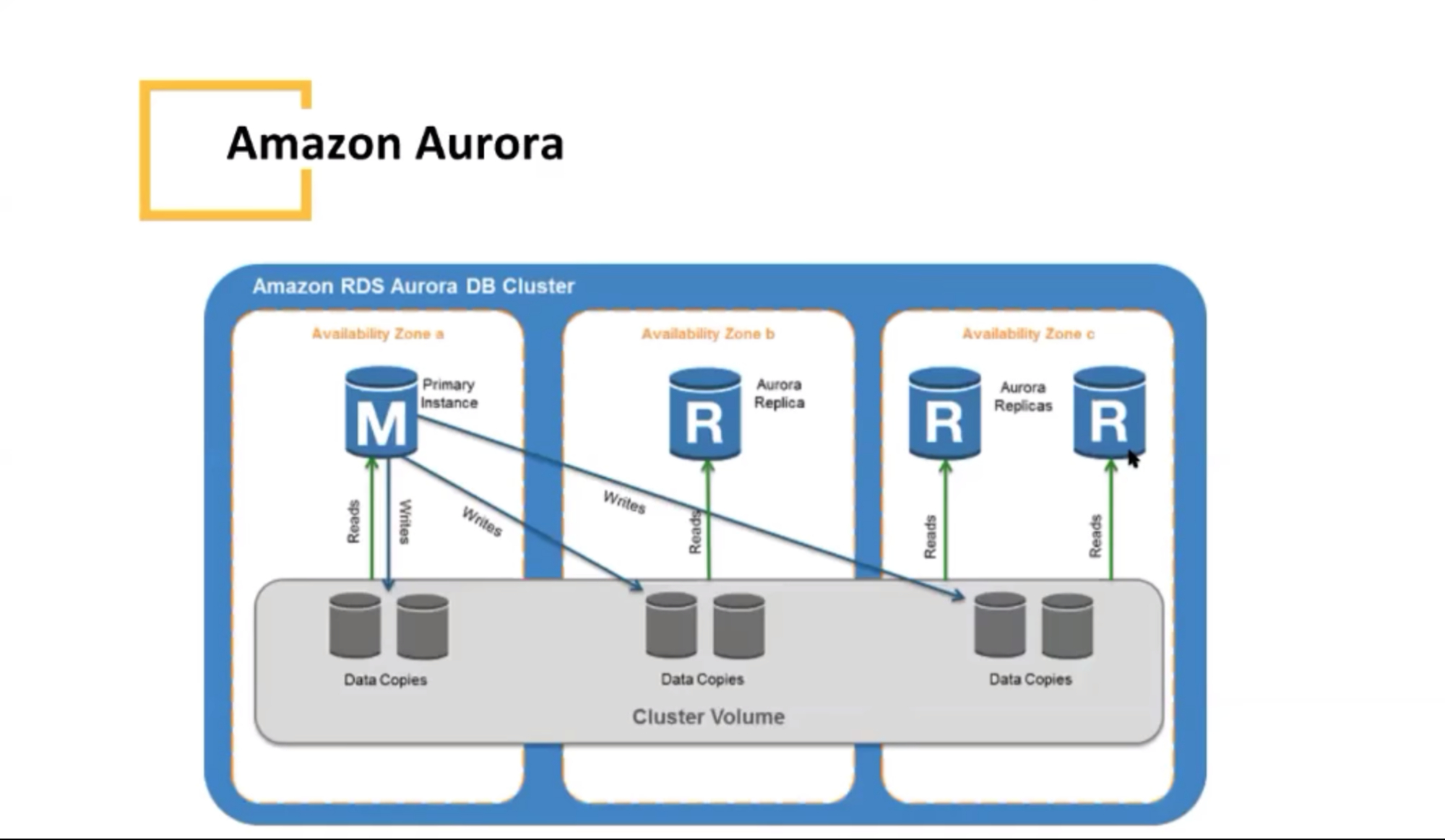
Amazon Aurora
Amazon Aurora介绍
底层利用共享存储
上层利用MySQLProxy接收用户SQL命令
优点:
兼容SQL
适合公有云
适合做多租户
缺点:
写入只有单节点,但读可以Replication扩展
什么是TiDB?
可扩展性是第一流的特征
SQL是必要的
在大多数情况下,与MySQL兼容
OLTP + OLAP = HTAP(混合交易/分析处理)
24/7的可用性,即使是在数据中心中断的情况下
当然,是开源的
优点:
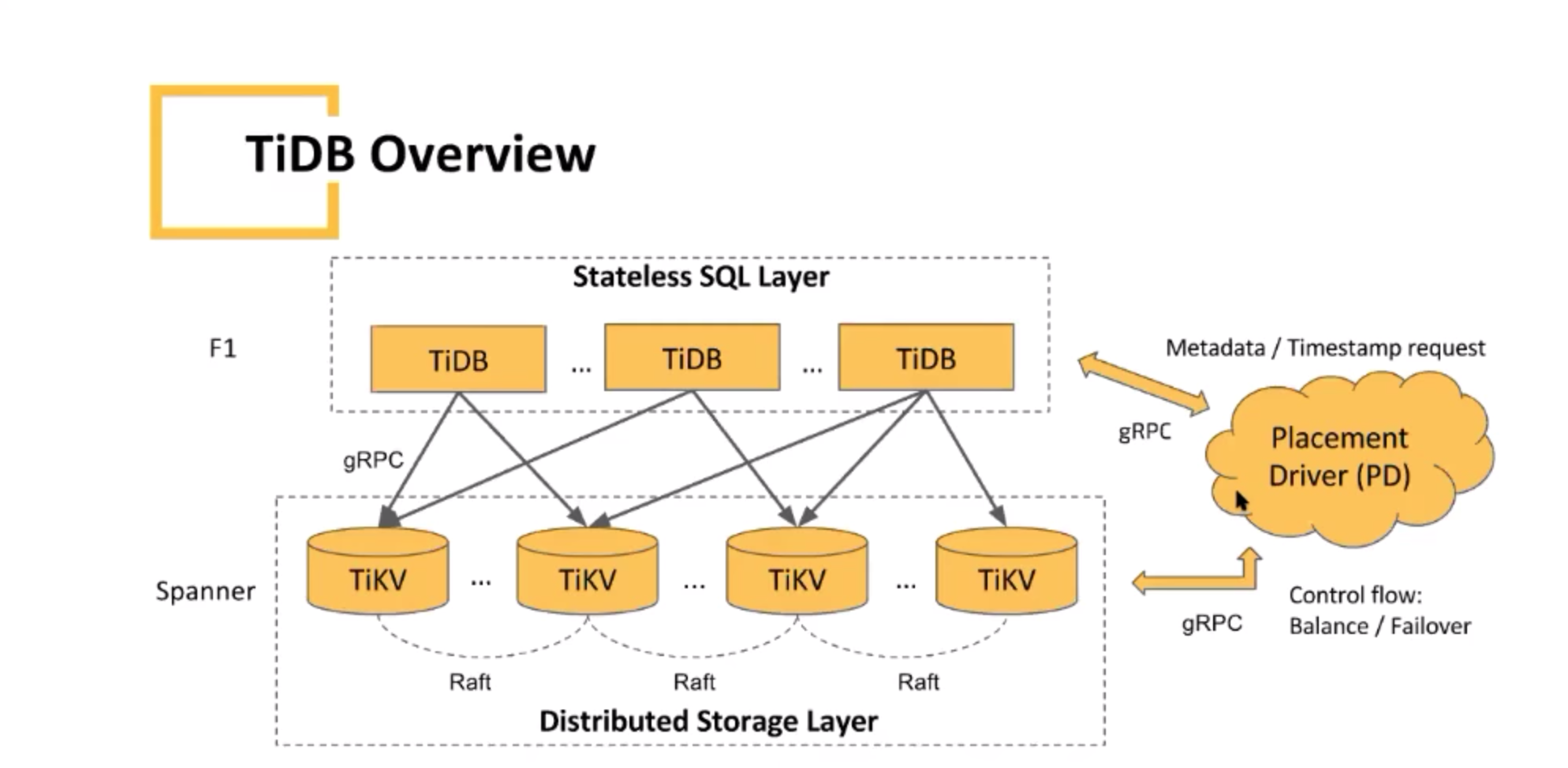
存储于计算分离,便于各部分扩展
架构:
TiDB: 无状态的SQL层(对标F1)
分布式SQL优化器/执行器
TiKV: 分布式KV存储引擎(对标Spanner)
MVCC
分布式事务(2PC)
PD: 元信息管理、集群管理和调度(拥有全局视角的跳读模块)
TiKV架构
RocksDB(一个持久型的K/V数据库) 比LevelDB好
BTrees vs LSM-Tree(SSTable)
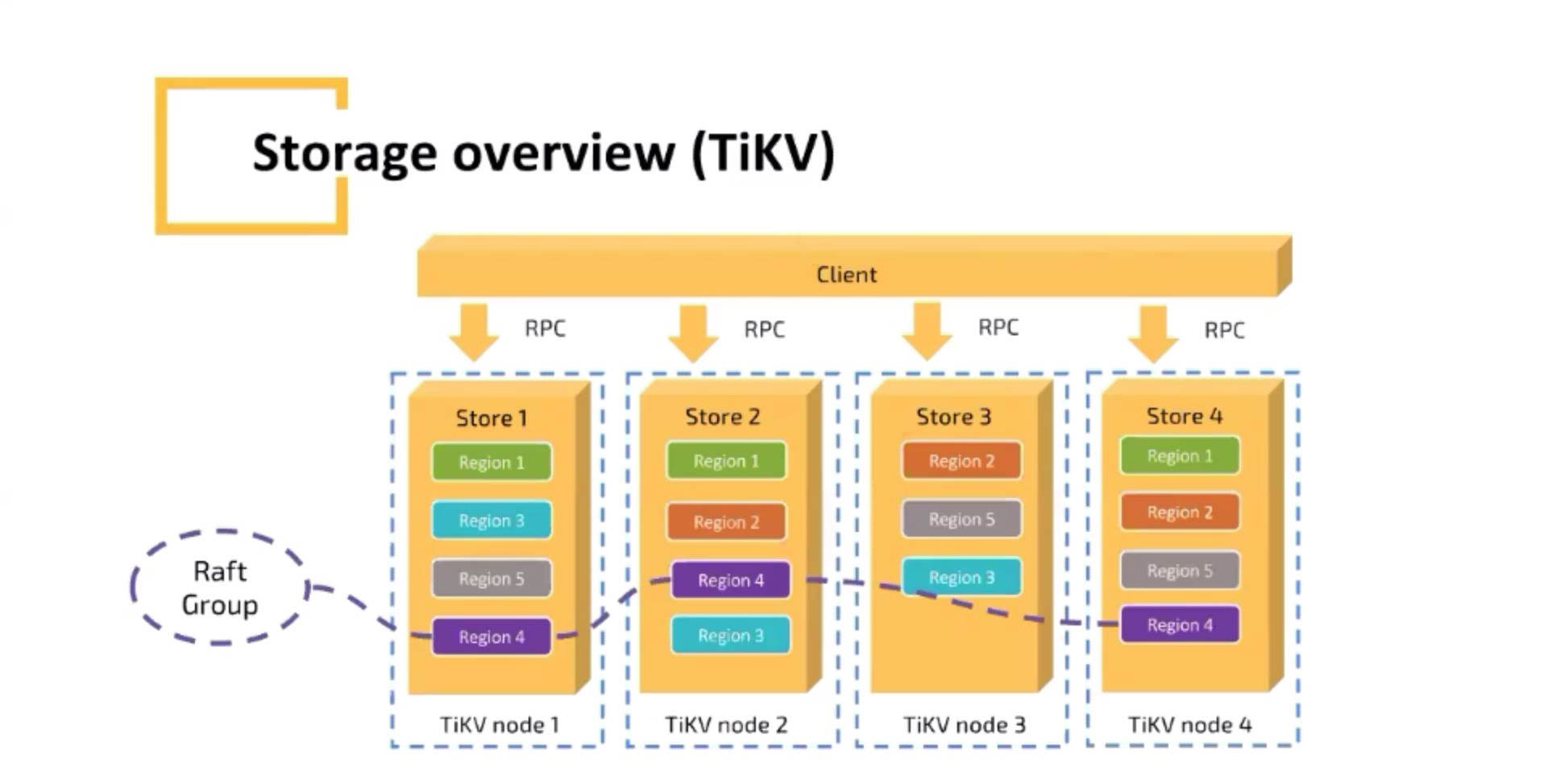
TiKV的关键设计
为什么是Raft?
工业级别的实现规范(Paoxs规范比较复杂,没有规范实现标准)
为什么是RocksDB?
如何支持MVCC和分布式事务?
分布式事务核心就是2PC
分布式难点是有一个全局时序(时间戳管理器来分配事务序号)
为什么不把它建立在分布式文件系统(HDFS/Ceph)之上?
为什么是MySQL方言?
用户多
开源
为什么不重复使用MySQL的源代码?
mysql是单机版
mysql的pase代码比较老,不如自己写
底层是KV
基于行的VS列的
后期智能把Row转成Column,行列共存
如何为OLTP和OLAP工作负载做资源隔离?
KV层有Job
如何支持大表的DDL?
单机只是锁表后就执行了
分布式不方便锁表,因为太大了。业务不阻塞的算法Google论文 Online, Asynchronous Schema Change in F1
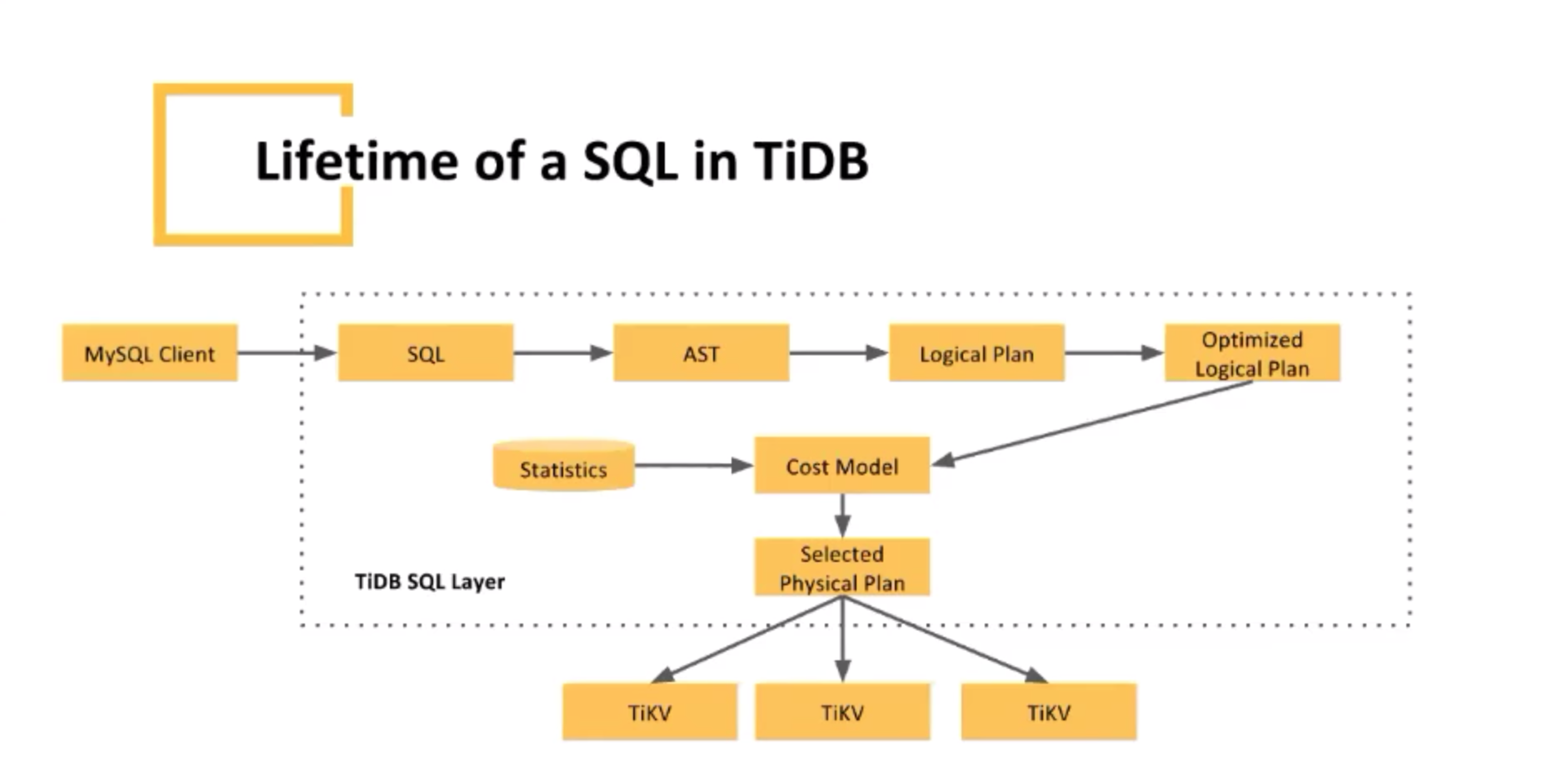
一条SQL的生命周期
客户端请求
转换SQL
抽象语法树
逻辑计划
分析逻辑计划
Cost Model 成本模型(<-静态分析)
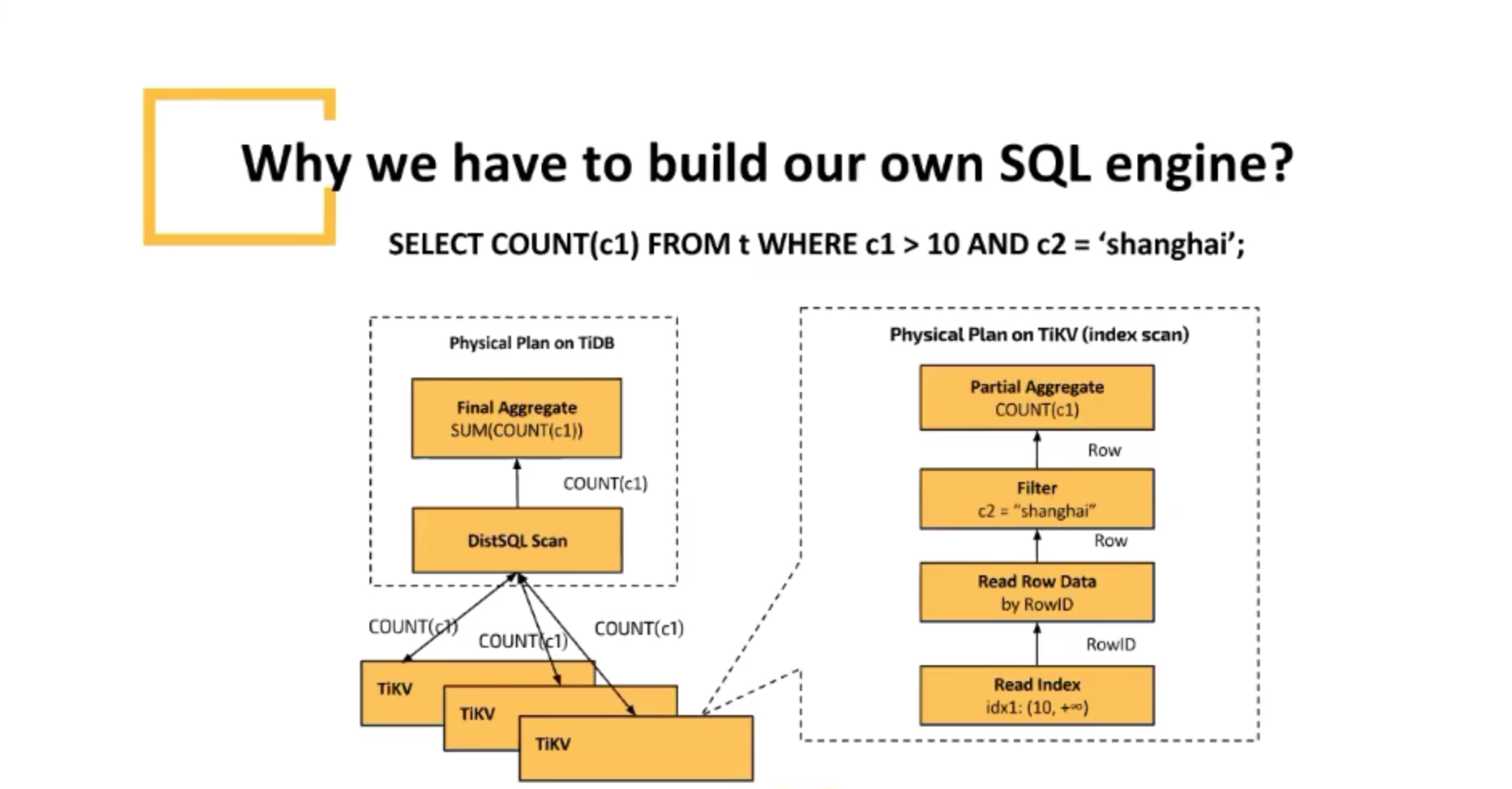
选择物理计划(分布式计算任务(有向无环图))
gRpc调用TiKV
分布式系统是脆弱的
~30个机架中约有5个发生故障(50%的数据包丢失)。
~8次网络维护(4次可能导致30分钟的随机连接损失)
~3个路由器故障(必须立即拉动流量一个小时)
可信赖的网络是一个神话
GC暂停/进程崩溃/调度延迟/网络维护/设备故障
测试事项
分布式系统的测试是非常困难的
测试驱动的开发
测试用例来自于通信
在MySQL驱动/连接中进行大量的测试
ORMs的丢失
丢失的应用程序(记录-重放)
故障注入
硬件:错误、网卡、Cpu、时钟
软件:文件系统、网络和协议、代码注入随机Bug(不是unit test只是加快问题出现)
模拟一切:网络
分布式测试
Jepsen
Namazu
学习途径
存储型论文
谷歌论文(GFS/BigTable/Spanner/F1)
共识算法(Raft/Paxos)
麻省理工学院 6.824
分布式计算系统(Spack/Dremel/Presto/Impala)
NewSQL系统(TiDB/CockroachDB)
加入开源项目
计算型论文
MapReduce
RDB
为什么列式存储加快
未来会是什么样子?
IO未来不是问题,那么应该用数据结构(NVE结构),现在用到BTree加速IO查询,未来用什么?
数据库未来是云原生,Kubernetes未来是操作系统,如果将DB融入K8S中。
OLAP与OLTP融合
