一个月前,AlphaFold 让 AI 算法预测蛋白质结构迎来了里程碑式的进展。就在今天,AI 算法预测 RNA 三维结构也取得突破性进展。
2021 年 8 月 27 日,斯坦福大学团队在 Science 发表了题为《RNA结构的几何深度学习》(Geometric deep learning of RNA structure)的封面文章。

图 | 本期 Science 封面(来源:Science)
相对来说,人们对 RNA 的结构知之略少,因此对其结构的预测更是充满挑战。在本次研究中,斯坦福大学团队提出一种基于深度机器学习的新方法,名字叫 ARES (Atomic Rotationally Equivariant Scorer)。
据悉,ARES 可在少量已知训练样本,即只有 18 种已知的 RNA 结构的前提下,实现对于 RNA 三维结构的精准预测。
谈及可给相关从业者带来的好处,西湖大学生命科学学院研究员黄晶告诉 DeepTech,Dror 的这个工作的精巧之处在于实际上他们提出了一种有效的神经网络架构用于训练大分子体系的打分函数,并将其应用于 RNA 的结构评估;训练得到的高精度打分函数和特定的 RNA 结构生成或采样方法相结合,就可以实现对于 RNA 三维结构的精准预测。
因为学习目标是用来评估一个给定 RNA 结构相对于其最优结构的差距的 RMSD 分值,所以从极少量已知的 RNA 结构出发,可以人工产生万级别的 RNA 结构及其对应的 RMSD 分值用做训练集,使得相应的模型训练成为可能。
而此前在 2020 年 12 月 2 日,斯坦福大学相关团队也发表过一篇论文,题为《用于选择蛋白质复合物结构模型的分层、旋转不变性神经网络》,当时发表在 Proteins 上。事实上,这两篇论文是同一研究的姊妹篇。

图 | 相关论文(来源:Proteins)
第一篇论文由斯坦福大学计算机科学副教授罗恩·卓尔(Ron O. Dror)主导,第二项研究由罗恩·卓尔和生物化学副教授瑞朱·达斯(Rhiju Das)共同领导。这两项研究都表明,RNA 的三维结构可被人工智能(AI)预测。
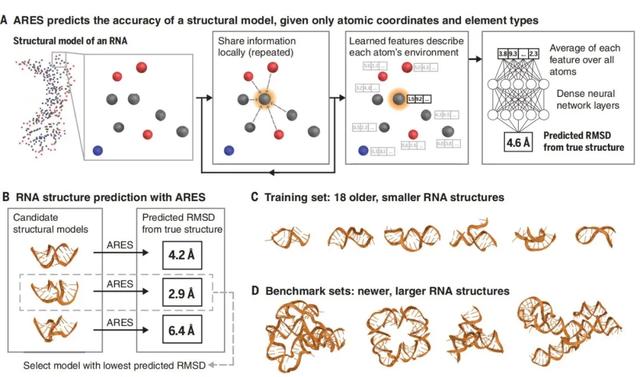
图 | 只给定原子坐标和元素类型,ARES 即可预测 RNA 结构模型的精度
此前用 AI 预测 RNA 的三维结构又难又贵
对 RNA 结构的深入理解对于许多生物学问题有着重要作用,也将大大促进核酸药物设计以及靶向核酸的小分子药物设计。
但是 RNA 的结构预测公认比蛋白质结构预测更加困难。困难的点表现在以下几个方面:
1)实验已经解出的RNA结构的数量远小于蛋白质的结构,因此训练数据严重缺乏;
2)多重序列比对中包含的共进化信息非常有效地提升了蛋白质结构预测的精度,但对于RNA结构预测帮助甚微;
3)RNA很有可能随环境不同存在多个稳定的结构态,理论方法最好能够无偏地搜索这些稳态。
因此,尽管经过了几十年的艰苦努力,预测 RNA 的三维空间结构仍然是一个巨大的挑战。相比预测蛋白质的三维结构,用机器学习算法来预测 RNA 的三维结构更具挑战性,计算成本也更昂贵。那么,算法是否可从已知的 RNA 结构中学习、以便评估不相关 RNA 结构模型的准确性?
(来源:Science)
要想实现上述能力,会给机器学习提出两个主要挑战:第一,在评价空间结构模型优劣时,避要免以人类的认知为参考;第二,要从实验确定的、有限数量的 RNA 结构中学习。
这种方法也叫无干预的深度学习方法,此前已在许多领域取得显著进展,但成功的前提是——有大量实验数据作为训练样本。
基于此,研究人员使用神经网络设计了 ARES 算法(Atomic Rotationally Equivariant Scorer)来解决这些挑战。
只接受 18 种已知 RNA 结构的训练,即可识别出准确的结构模型
事实上,机器学习领域的多数重大进展,均需训练大量数据比如 GPT-3 等,而 ARES 在极少训练数据下就能成功。尽管只用几个RNA 结构进行训练,但 ARES 却比此前算法更优秀。这说明在数据有限、且收集成本极高的三维分子测构领域,类似的 AI 算法有望大显神威。
ARES 由许多处理层组成,每一层的输出可作为下一层的输入。由于它含有独特的架构,因此能直接从三维结构中学习,并在非常少量的实验数据中进行有效学习。
ARES 的初始层可用于识别结构主题,这些结构主题的身份不是预先指定的,而是由机器在训练过程中自己发现和总结的。每一层网络都会根据周围原子的几何排列和前一层计算的特征,去计算每个原子的几个特征。
(来源:Science)
ARES 的初始层会在局部收集信息,其余层则会跨越所有原子进行信息收集,这种组合允许 ARES 预测一个分子的全局属性,同时还可详细记录局部结构基序和原子间的相互作用。
不过,ARES 不包含任何有关结构模型的假设,比如它并不涉及双螺旋、碱基对、核苷酸或氢键的概念,它的训练方法也不特定于 RNA,因此适用于任何类型的分子系统。
新南威尔士大学副教授姚丽娜告诉 DeepTech,对 ARES 来说,只需给定一个 RNA 的三维结构作为输入,它就能基于每个原子与周围原子的几何特征,逐层自动学习到有意义的结构化基元信息,并预测出 RNA 三维分子模型。
也就是说在训练 ARES 时,研究人员并没有告知该算法、具体哪些分子特征会让结构预测更准确,而是让算法自己去发现。这样做是因为如果为机器提供额外的“学习资料”,会使算法偏向于选择某些特征,如此就会阻止它找到其他新特征。
(来源:Science)
预测出的模型会和训练集给定的 ground-truth 模型不断进行比对,从而持续进行反向调整,并对 ARES 的各个参数加以优化,直到达到最优预测结果。
尽管 ARES 只接受了 18 种已知 RNA 结构的训练,但它能够识别准确的结构模型,而不需要假设它们的定义特征。
该团队还优化了 ARES 的参数,从而让它的输出、尽可能接近相应结构的每个模型的均方根偏差值。
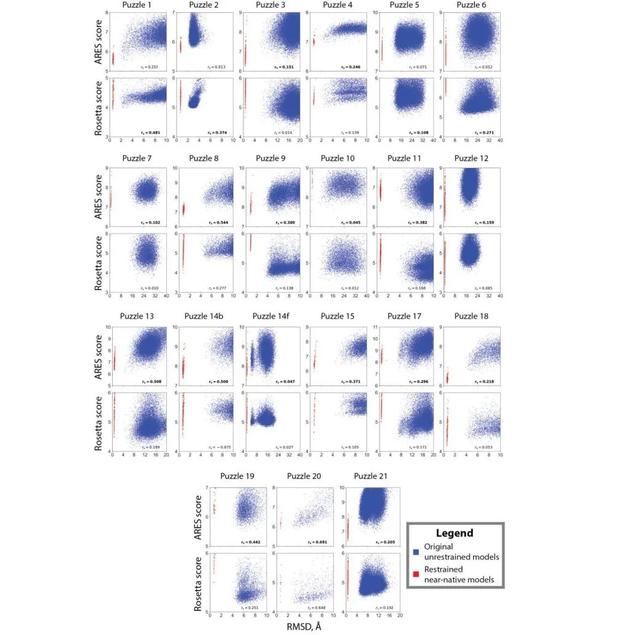
为了评估 ARES 预测 RNA 空间结构的能力,研究人员使用了一个由RNA模糊结构的预测挑战,其中包含的所有 RNA 都是 2010 年至 2017 年期间发表且已经被测序的。
对于每个 RNA,研究人员使用 FARFAR2 生成了至少 1500 个结构模型,为确保一些模型接近原生模型,即在实验确定的原生结构的 2-ARMSD 内,在为每个 RNA 生成 1% 的模型时,他们对原生结构的坐标进行了能量约束。这时再使用训练后的 ARES 网络,就能为每个模型生成一个评分。
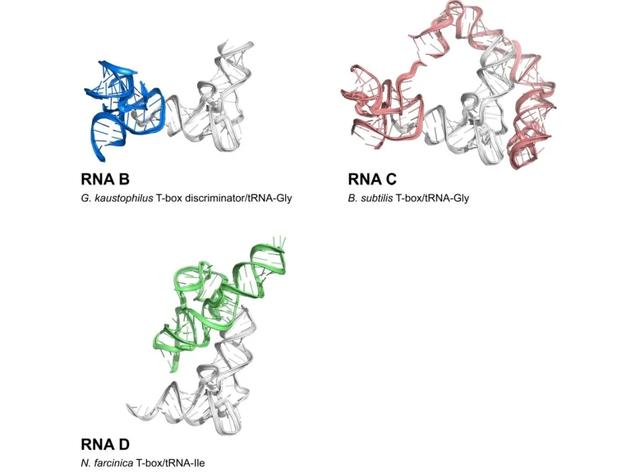
(来源:Science)
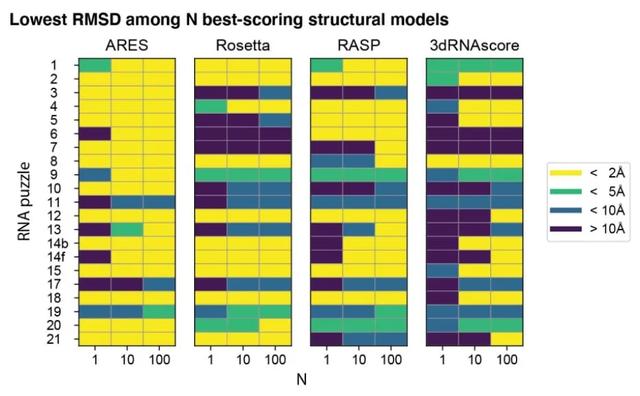
该团队还使用三个最先进的评分函数,来对每个模型进行评分:其余三个模型分别是最新版本的 Rosetta、RASP、以及 3dRNAscore。在第一个基准测试上,ARES 的性能大大优于其他三个评分功能:比如 62% 的基准 RNA 的单一最佳评分结构模型接近原生,且均高于其他三个模型。
由于目前对候选结构模型进行抽样的方法,往往不能在合理计算时间内生成接近标准答案的模型。因此,研究人员编译了第二个基准测试,其中不包括接近本地的模型。
他们还选择了 16 个结构多样的 RNA,这些都与用于训练 ARES 的 RNA、以及此前基准大不相同,每个都包含一个或多个结构复杂的大厅标记,例如配体结合位点、多路连接和三级接触。
随后,他们使用 ARES 和其他六个在过去 14 年中被广泛使用的评分函数对所有模型进行了评分。在第二个基准测试上,ARES 再次完成了所有评分功能。而且,ARES 的最佳评分结构模型的 RNA 的中位数均方根偏差值,明显低于其他评分函数。
(来源:Science)
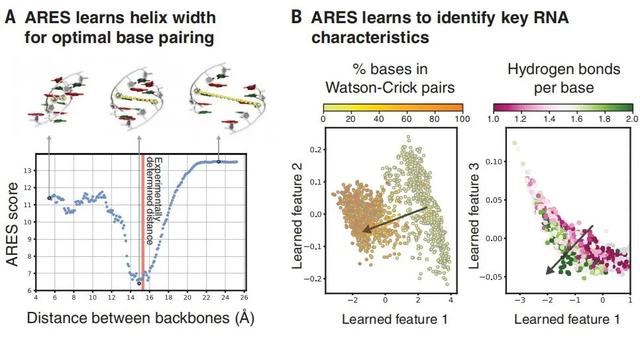
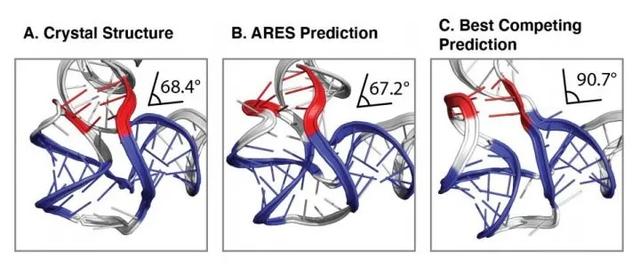
对训练后的 ARES 的分析表明,它独立发现了 RNA 结构的某些基本特征。举例来说,ARES 能正确预测双螺旋中两条链之间的最佳距离,即允许理想碱基配对的距离。
尽管研究人员从未告知 ARES:氢键和碱基配对是 RNA 结构形成的关键驱动因素。但是在 ARES 发现的更高级别的特征中,依然能反映每个结构中氢键和 Watson-Crick 碱基配对的程度。此外,ARES 还能准确识别复杂的三级结构元素,包括在训练数据集中没有表示的元素。
(来源:Science)
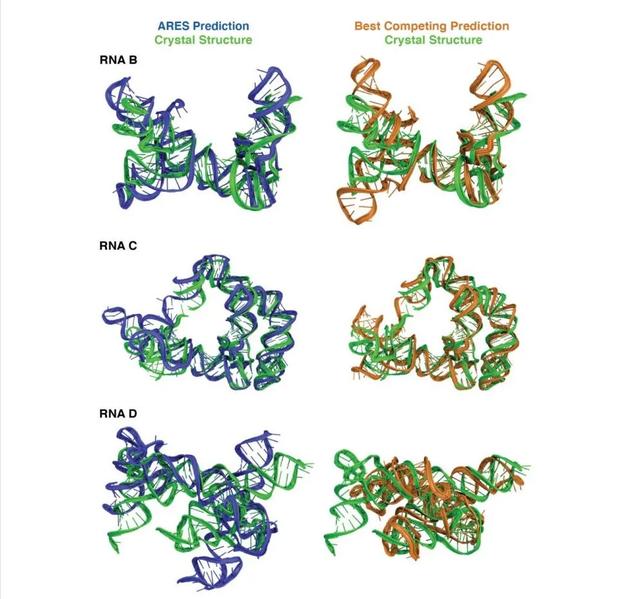
该团队认为 ARES 的性能特别显著,因为所有用于盲结构预测、以及大多数用于系统基准测试的 RNA,都比用于训练 ARES 的 RNA 更复杂。
概括来说,ARES 具备两大优势:其一,它可基于极少训练样本进行学习;其二,使用时无需提前假设基元(motif)信息,也无需考虑是否会对预测结果产生正面影响或负面影响,模型会在训练过程中自动决定和学习更有价值的特征,从而更精准地预测未知的RNA 三维分子结构。
除了结构预测之外,也有望用于药物设计和电磁性能估计等
而 ARES 目前一个待优化的地方是,它依赖于先前开发的抽样方法来生成候选结构模型。故此,该团队计划使用 ARES 来指导抽样,以提高最佳可教学模型的准确性。通过结合其他类型的实验数据,比如低分辨率低温电子显微镜和化学定位数据,即可加以改进。
总体来看,该团队认为尽管只使用少量结构进行训练,但 ARES 的能力仍优于之前的技术,因此这类算法有望让涉及三维分子结构的其他领域取得实质性进展。
(来源:Science)
除了结构预测外,应用场景可能还包括药物设计(蛋白质或核酸等大分子和小分子药物)、纳米颗粒半导体的电磁性能估计、以及合金和其他材料的力学性能预测等。
姚丽娜表示:“ARES 对我们对于 RNA 结构的更深入的认识和相关研究提供非常有价值的手段。比如,目前肆虐全球的新冠病毒,就是 RNA 病毒,ARES 此类工作个人认为会对我们预测病毒的变异,以及开发针对病毒的有效的疫苗会产生巨大的促进作用。”


