机器学习可视化
小白学视觉2020-11-08 12:51
0.简介
作为任何数据科学项目的一部分,数据可视化起着重要的作用,通过它可以了解有关可用数据的更多信息并确定任何主要模式。
如果能够使分析中的机器学习部分尽可能在视觉上变得直观,那不是很好吗?
在本文中,我们将探索一些可以帮助我们应对这一挑战的技术,例如:平行坐标图(Parallel Coordinate Plots),汇总数据表(Summary Data Tables ),绘制ANN图等。
1.相关技术
1.1 超参数优化(Hyperparameters Optimization)
超参数优化是机器/深度学习中最常见的活动之一。机器学习模型调整是一种优化问题。我们有一组超参数(例如学习率,隐藏单位数等),我们的目标是找出它们的值的正确组合,这可以帮助我们找到最小值(例如损耗)或函数的最大值(准确性)。
在2D空间中,此类任务的最佳解决方案之一是使用平行坐标图(图1)。使用这种类型的图,我们实际上可以轻松地将不同的变量(例如特征)进行比较,以发现可能的关系。在“超参数优化”的情况下,它可以用作检查哪些参数组合可以为我们提供最大测试精度的简单工具。数据分析中平行坐标图的另一种可能用途是检查数据框中不同要素之间的值之间的关系。
在图1中,提供了使用Plotly创建的实际示例。
import plotly.express as pxfig = px.parallel_coordinates(df2, color="mean_test_score",labels=dict(zip(list(df2.columns),list(['_'.join(i.split('_')[1:]) for i in df2.columns]))),color_continuous_scale=px.colors.diverging.Tealrose,color_continuous_midpoint=27)fig.show()
 图1. 平行坐标超参数优化图
图1. 平行坐标超参数优化图为了在Python中创建平行坐标图,可以使用不同的技术,例如使用Pandas,Yellowbrick,Matplotlib或Plotly。
最后,可以使用另一种可能的方法来创建这种类型的绘图,方法是使用“权重和偏移扫描(Weights&Biases Sweeps)”功能。权重和偏差是一个免费工具,可用于为个人或团队自动创建不同机器学习任务(例如,学习曲线,图形模型等)的图和日志。
1.2数据包装器(Data Wrapper)
DataWrapper是一个免费的在线工具,专门用于创建专业图表。例如,该工具在《纽约时报》,《 Vox》和《有线》等期刊的文章中使用。无需登录,所有过程都可以完全在线完成。
今年还为此工具创建了一个Python包装器。可以使用以下方法轻松安装:
pip install datawrapper为了使用Python API,我们还需要注册Data Wrapper,进入设置并创建API密钥。使用此API密钥,我们便可以远程使用Data Wrapper。
此时,例如,通过使用以下几行代码并将Pandas数据框作为create_chart函数的输入,我们可以轻松创建条形图。
from datawrapper import Datawrapperdw = Datawrapper(access_token = "TODO")games_chart = dw.create_chart(title = "Most Frequent Game Publishers", chart_type = 'd3-bars', data = df)dw.update_description(games_chart['id'],source_name = 'Video Game Sales',source_url = 'https://www.kaggle.com/gregorut/videogamesales',byline = 'Pier Paolo Ippolito',)dw.publish_chart(games_chart['id'])
 图2. 数据包装器条形图
图2. 数据包装器条形图发布图表后,我们就可以在数据包装程序帐户的已创建图表列表中找到它。点击我们的图表,我们将找到一个不同选项的列表,我们可以使用这些选项轻松共享我们的图表(例如,嵌入,HTML,PNG等)。
1.3 预测表
在使用时间序列数据时,有时可以快速地了解我们的模型在哪些数据点上的表现不佳,以便尝试了解它可能面临的局限性,这确实非常方便。
一种可能的方法是创建一个具有实际值和预测值以及某种形式的度量的汇总表,以汇总数据点的预测好坏。
使用Plotly,可以通过创建绘图功能轻松完成此操作:
import chart_studio.plotly as pyimport plotly.graph_objs as gofrom plotly.offline import init_notebook_mode, iplotinit_notebook_mode(connected=True)import plotlydef predreport(y_pred, Y_Test):diff = y_pred.flatten() - Y_Test.flatten()perc = (abs(diff)/y_pred.flatten())*100priority = []for i in perc:if i > 0.4:priority.append(3)elif i> 0.1:priority.append(2)else:priority.append(1)print("Error Importance 1 reported in ", priority.count(1),"cases\n")print("Error Importance 2 reported in", priority.count(2),"cases\n")print("Error Importance 3 reported in ", priority.count(3),"cases\n")colors = ['rgb(102, 153, 255)','rgb(0, 255, 0)','rgb(255, 153, 51)', 'rgb(255, 51, 0)']fig = go.Figure(data=[go.Table(header=dict(values=['Actual Values', 'Predictions','% Difference', "Error Importance"],line_color=[np.array(colors)[0]],fill_color=[np.array(colors)[0]],align='left'),cells=dict(values=[y_pred.flatten(),Y_Test.flatten(),perc, priority],line_color=[np.array(colors)[priority]],fill_color=[np.array(colors)[priority]],align='left'))])init_notebook_mode(connected=False)py.plot(fig, filename = 'Predictions_Table', auto_open=True)fig.show()调用此函数将得到以下输出:
Error Importance 1 reported in 34 casesError Importance 2 reported in 13 casesError Importance 3 reported in 53 cases
 图3. 预测表格
图3. 预测表格1.4 决策树(Decision Tree)
决策树是机器学习模型中最容易解释的类型之一。由于它们的基础结构,可以很容易地通过查看树的不同分支上的条件来检查算法是如何做出决定的。此外,考虑到算法将决策树认为对我们所需的分类/回归任务最有价值的特征放在树的顶层,因此决策树也可以用作特征选择技术。这样,由于携带较少的信息,可以丢弃树底部的特征。
可视化分类/回归决策树的最简单方法之一是使用sklearn.tree中的export_graphviz。在本文中,使用dtreeviz库提供了另一种更完整的方法。
使用此库,只需使用以下几行代码即可创建分类决策树:
from dtreeviz.trees import *viz = dtreeviz(clf,X_train,y_train.values,target_name='Genre',feature_names=list(X.columns),class_names=list(labels.unique()),histtype='bar',orientation ='TD')viz
 图4. 决策树分类
图4. 决策树分类在图4中,不同的类别用不同的颜色表示。所有不同类的特征分布在树的起始节点中表示。只要我们向下移动每个分支,算法便会尝试使用每个节点图下方描述的功能来最好地分离不同的分布。分布旁边生成的圆表示跟随某个节点后正确分类的元素数量,元素数量越大,圆的大小越大。
图5显示了使用决策树回归器的示例。
 图4. 决策树分类
图4. 决策树分类1.5 决策边界(Decision Boundaries)
决策边界是以图形方式了解机器学习模型如何进行预测的最简单方法之一。在Python中绘制决策边界的最简单方法之一就是使用Mlxtend。实际上,该库可用于绘制机器学习和深度学习模型的决策边界。一个简单的示例如图6所示。
from mlxtend.plotting import plot_decision_regionsimport matplotlib.pyplot as pltimport matplotlib.gridspec as gridspecimport itertoolsgs = gridspec.GridSpec(2, 2)fig = plt.figure(figsize=(10,8))clf1 = LogisticRegression(random_state=1,solver='newton-cg',multi_class='multinomial')clf2 = RandomForestClassifier(random_state=1, n_estimators=100)clf3 = GaussianNB()clf4 = SVC(gamma='auto')labels = ['Logistic Regression','Random Forest','Naive Bayes','SVM']for clf, lab, grd in zip([clf1, clf2, clf3, clf4],labels,itertools.product([0, 1], repeat=2)):clf.fit(X_Train, Y_Train)ax = plt.subplot(gs[grd[0], grd[1]])fig = plot_decision_regions(X_Train, Y_Train, clf=clf, legend=2)plt.title(lab)plt.show()
 图6. 决策边界
图6. 决策边界Mlxtend的一些可能替代方法是:Yellowbrick,Plotly或普通的Sklearn和Numpy实现。
绘制决策边界的主要限制之一是它们只能在二维或三维中轻松显示。由于这些限制,因此在绘制决策边界之前,大多数时候可能有必要减少我们输入特征的维数(使用某种形式的特征提取技术)。
1.6 人工神经网络(Artificial Intelligent Network)
创建新的神经网络架构时,另一种可能非常有用的技术是可视化其结构。使用ANN Visualiser可以很容易地做到这一点(图7)。
from keras.models import Sequentialfrom keras.layers import Densefrom ann_visualizer.visualize import ann_vizmodel = Sequential()model.add(Dense(units=4,activation='relu',input_dim=7))model.add(Dense(units=4,activation='sigmoid'))model.add(Dense(units=2,activation='relu'))ann_viz(model, view=True, filename="example", title="Example ANN")

图7. 人工神经网络示意图
1.7 Livelossplot
在训练和验证过程中自动能够实时绘制神经网络的损失和准确性可能会很有帮助,以便立即查看网络是否随时间推移取得了进展。使用Livelossplot可以很容易地做到这一点。
使用Livelossplot,可以通过将我们要记录的所有度量存储在字典中并在每次迭代结束时更新图来轻松完成此操作。如果我们有兴趣创建多个图形(例如,一个用于损耗图,一个用于整体精度图),则可以应用相同的过程。
from livelossplot import PlotLossesliveloss = PlotLosses()for epoch in range(epochs):logs = {}for phase in ['train', 'val']:losses = []if phase == 'train':model.train()else:model.eval()for i, (inp, _) in enumerate(dataloaders[phase]):out, z_mu, z_var = model(inp)rec=F.binary_cross_entropy(out,inp,reduction='sum')/inp.shape[0]kl=-0.5*torch.mean(1+z_var-z_mu.pow(2)-torch.exp(z_mu))loss = rec + kllosses.append(loss.item())if phase == 'train':optimizer.zero_grad()loss.backward()optimizer.step()prefix = ''if phase == 'val':prefix = 'val_'logs[prefix + 'loss'] = np.mean(losses)liveloss.update(logs)liveloss.send()Livelossplot还可与其他库一起使用,例如Keras,Pytorch-Lightin,Bokeh等。
1.8 变体自动编码器(Variational Autoencoders)
变分自动编码器(VAE)是一种概率生成模型,用于创建某些输入数据(例如图像)的潜在表示,这些输入数据可以简洁地理解原始数据并从中生成全新的数据(例如,训练VAE模型)具有不同的汽车设计图像,然后可以进行建模以创建全新的富有想象力的汽车设计)。
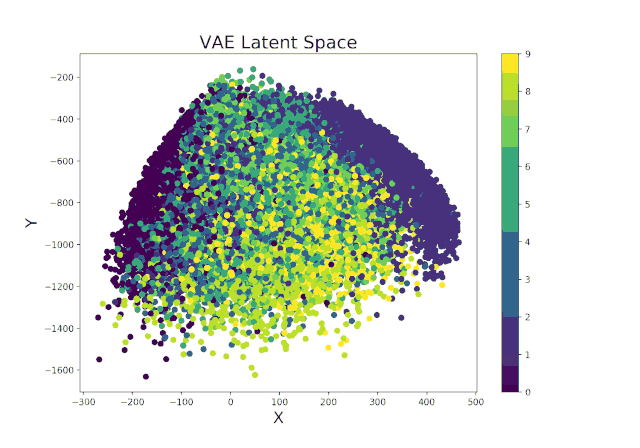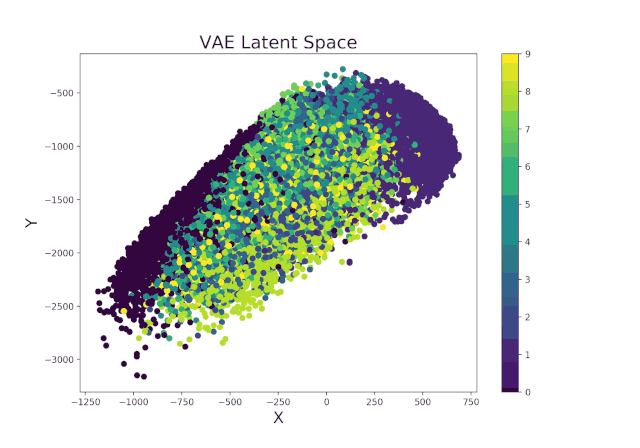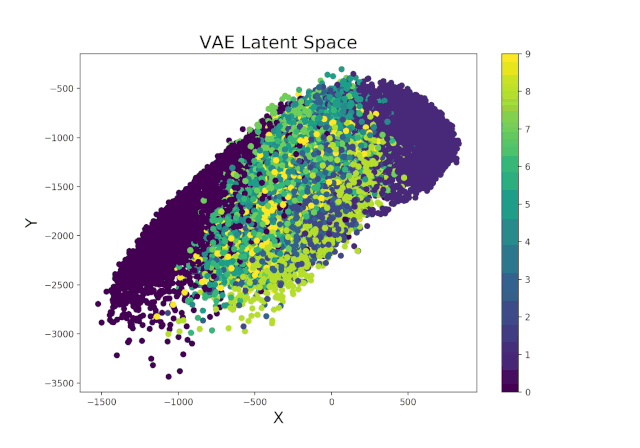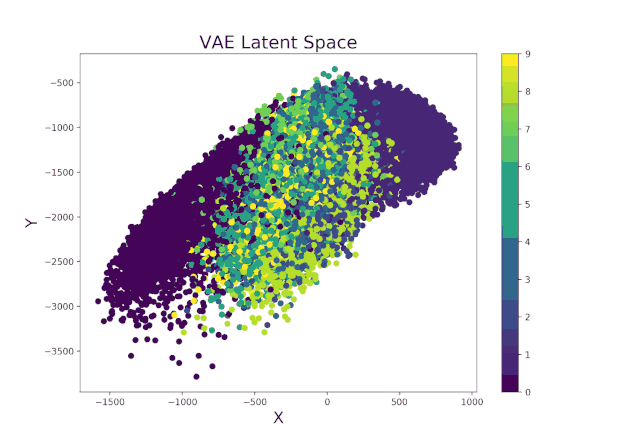
继续使用Livelossplot训练的示例变分自动编码器,我们甚至可以通过检查潜在空间(图8)从一次迭代到另一次迭代的变化(以及因此我们的模型在区分时间上的不同而改进了多少)来使我们的模型更加有趣。。
通过在先前的训练循环中添加以下功能,可以轻松完成此操作:
def latent_space(model, train_set, it=''):x_latent = model.enc(train_set.data.float())plt.figure(figsize=(10, 7))plt.scatter(x_latent[0][:,0].detach().numpy(),x_latent[1][:,1].detach().numpy(),c=train_set.targets)plt.colorbar()plt.title("VAE Latent Space", fontsize=20)plt.xlabel("X", fontsize=18)plt.ylabel("Y", fontsize=18)plt.savefig('VAE_space'+str(it)+'.png', format='png', dpi=200)plt.show()
 图8. VAE潜在空间演变
图8. VAE潜在空间演变最后,可以应用类似的过程以实时显示VAE在生成逼真的图像中从迭代到迭代的改进方法(图9)。
def manifold(model, it='', n=18, size=28):result = torch.zeros((size * n, size * n))# Defyining grid spaces, s2 = torch.linspace(-7, 7, n), torch.linspace(7, -7, n)grid_x, grid_y = torch.std(s)*s, torch.std(s2)*s2for i, y_ex in enumerate(grid_x):for j, x_ex in enumerate(grid_y):z_sample = torch.repeat_interleave(torch.tensor([[x_ex, y_ex]]),repeats=batch_size, dim=0)x_dec = model.dec(z_sample)element = x_dec[0].reshape(size, size).detach()result[i * size: (i + 1) * size,j * size: (j + 1) * size] = elementplt.figure(figsize=(12, 12))plt.title("VAE Samples", fontsize=20)plt.xlabel("X", fontsize=18)plt.ylabel("Y", fontsize=18)plt.imshow(result, cmap='Greys')plt.savefig('VAE'+str(it)+'.png', format='png', dpi=300)plt.show()
 图9. 随着时间的推移,VAE不断改进,以
图9. 随着时间的推移,VAE不断改进,以1.9 词嵌入(Word Embeddings)
神经网络嵌入是一类神经网络,旨在学习如何将某种形式的分类数据转换为数值数据。考虑到在转换数据的同时,它们能够了解其特征并因此构造更简洁的表示形式(创建潜在空间),因此使用嵌入可能比使用其他技术(例如“一次热编码”)更具优势。预训练词嵌入中最著名的两种类型是word2vec和Glove。
作为一个简单的例子,我们现在将绘制一个表示不同书籍作者的嵌入空间。首先,我们需要根据一些可用数据创建一个训练模型,然后访问训练后的模型嵌入层的权重(在本例中为embed)并将它们存储在数据框中。完成此过程后,我们仅需绘制三个不同的坐标即可。
import matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import axes3d, Axes3Dembedding_weights=pd.DataFrame(model.embed.weight.detach().numpy())embedding_weights.columns = ['X1','X2','X3']fig = plt.figure(num=None, figsize=(14, 12), dpi=80,facecolor='w', edgecolor='k')ax = plt.axes(projection='3d')for index, (x, y, z) in enumerate(zip(embedding_weights['X1'],embedding_weights['X2'],embedding_weights['X3'])):ax.scatter(x, y, z, color='b', s=12)ax.text(x, y, z, str(df.authors[index]), size=12,zorder=2.5, color='k')ax.set_title("Word Embedding", fontsize=20)ax.set_xlabel("X1", fontsize=20)ax.set_ylabel("X2", fontsize=20)ax.set_zlabel("X3", fontsize=20)plt.show()可以用来可视化分类数据的另一种有趣的技术是Wordclouds(图10)。例如,可以通过创建书籍作者姓名及其在数据集中的频率计数的词典来实现这种表示形式。然后,在数据集中出现频率更高的作者将在图中以更大的字体表示。
from wordcloud import WordCloudd = {}for x, a in zip(df.authors.value_counts(),df.authors.value_counts().index):d[a] = xwordcloud = WordCloud()wordcloud.generate_from_frequencies(frequencies=d)plt.figure(num=None, figsize=(12, 10), dpi=80, facecolor='w',edgecolor='k')plt.imshow(wordcloud, interpolation="bilinear")plt.axis("off")plt.title("Word Cloud", fontsize=20)plt.show()
 图10. Worldcloud
图10. Worldcloud1.10 可解释的人工智能(Explainable AI)
如今,可解释的人工智能是一个不断发展的研究领域。最近,在决策应用程序(例如就业)中使用AI引起了个人和政府的关注。这是因为,当使用深度神经网络时,当前(至少在整个范围内)无法理解算法在必须执行预定任务时执行的决策过程。由于决策过程缺乏透明度,公众可能会对模型本身的可信赖性产生困惑。因此,为了防止AI模型中存在任何形式的偏差,现在对可解释AI的需求已成为下一个优先的进化步骤。
在过去的几年中,为了使机器学习更具解释性,引入了各种可视化技术,例如:
探索卷积神经网络过滤器和特征图。图网络。基于贝叶斯的模型。因果推理应用于机器学习。本地/全局代理模型。介绍了本地可解释模型不可知性解释(LIME)和Shapley值。如果您想了解更多有关如何使机器学习模型更易于解释的信息,那么Pytorch和XAI就是Captum的两个最有趣的库,它们是Python中当前可用的,以便将可解释AI应用于深度学习。
随着该研究领域的不断发展,我将在以后的文章中专门讨论可解释的AI,以涵盖所有这些(以及更多)不同的主题。
举报/反馈

0
0
收藏
分享
