
阿里妹导读
对于一个架构师来说,在软件开发中如何降低系统复杂度是一个永恒的挑战。
一、为什么需要DDD
复杂系统设计:系统多,业务逻辑复杂,概念不清晰,有什么合适的方法帮助我们理清楚边界,逻辑和概念?
多团队协同:边界不清晰,系统依赖复杂,语言不统一导致沟通和理解困难。有没有一种方式把业务和技术概念统一,大家用一种语言沟通。例如:航程是大家所理解的航程吗?
设计与实现一致性:PRD,详细设计和代码实现天差万别。有什么方法可以把业务需求快速转换为设计,同时还要保持设计与代码的一致性?
架构统一,可复用资产和扩展性:当前取决于开发的同学具备很好的抽象能力和高编程的技能。有什么好的方法指导我们做抽象和实现。
二、DDD的价值
边界清晰的设计方法:通过领域划分,识别哪些需求应该在哪些领域,不断拉齐团队对需求的认知,分而治之,控制规模。
统一语言:团队在有边界的上下文中有意识地形成对事物进行统一的描述,形成统一的概念(模型)。
业务领域的知识沉淀:通过反复论证和提炼模型,使得模型必须与业务的真实世界保持一致。促使知识(模型)可以很好地传递和维护。
面向业务建模:领域模型与数据模型分离,业务复杂度和技术复杂度分离。
三、DDD架构
3.1 分层架构
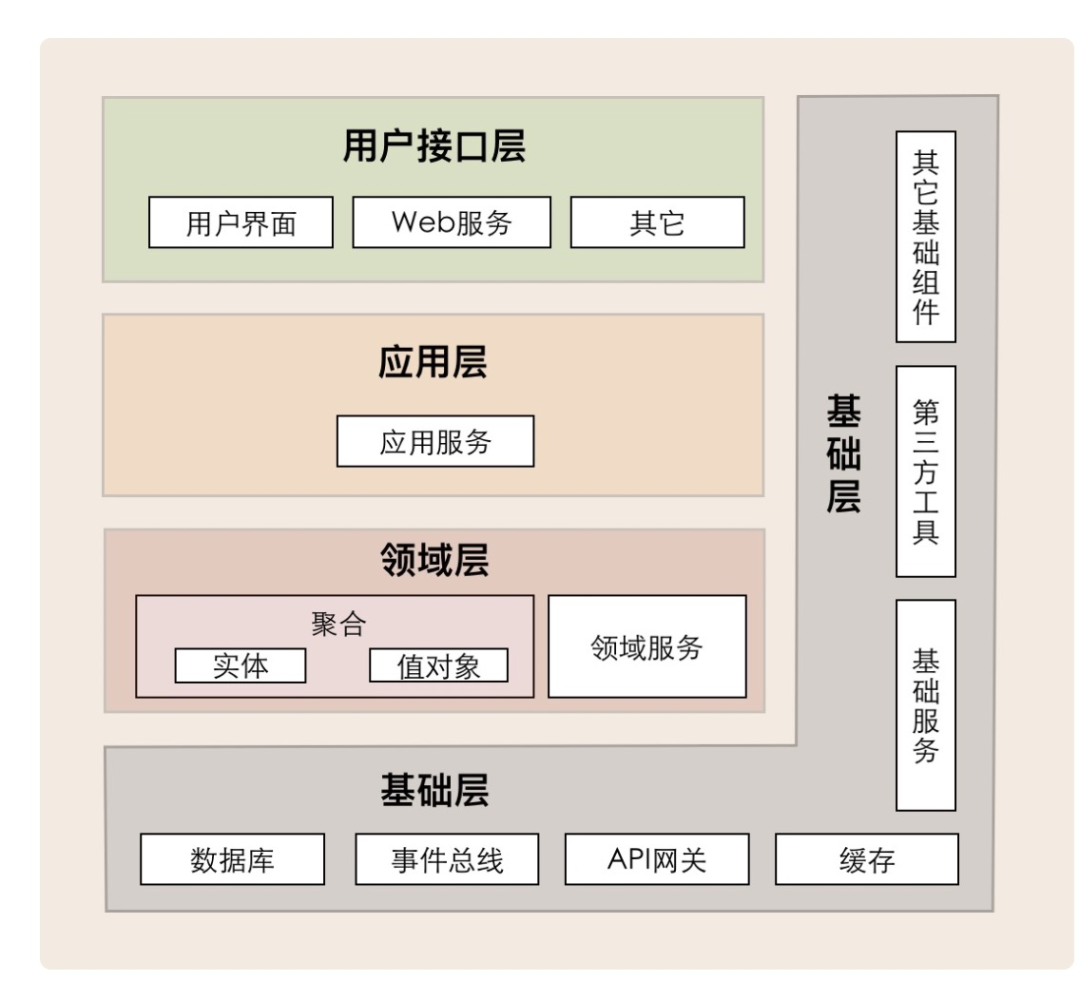
用户接口层:调用应用层完成具体用户请求。包含:controller,远程调用服务等
应用层App:尽量简单,不包含业务规则,而只为了下一层中的领域对象做协调任务,分配工作,重点对领域层做编排完成复杂业务场景。包含:AppService,消息处理等
领域层Domain:负责表达业务概念和业务逻辑,领域层是系统的核心。包含:模型,值对象,域服务,事件
基础层:对所有上层提供技术能力,包括:数据操作,发送消息,消费消息,缓存等
调用关系:用户接口层->应用层->领域层->基础层
依赖关系:用户接口层->应用层->领域层->基础层
3.2 六边形架构
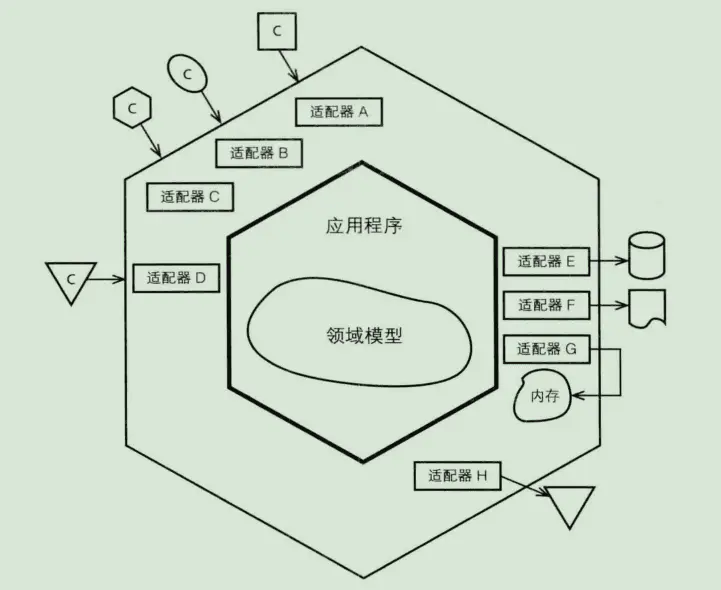
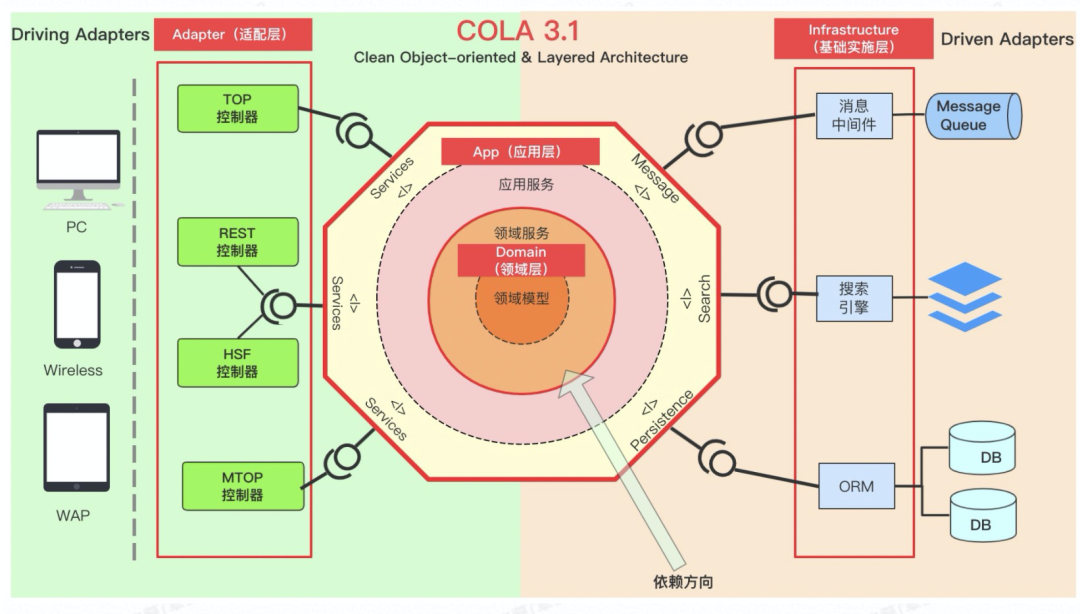
六边形架构:系统通过适配器的方式与外部交互,将应用服务于领域服务封装在系统内部
分层架构:它依然是分层架构,它核心改变的是依赖关系。
领域层依赖倒置:领域层依赖基础层倒置成基础层依赖领域层,这个简单的变化使得领域层不依赖任务层,其他层都依赖领域层,使得领域层只表达业务逻辑且稳定。
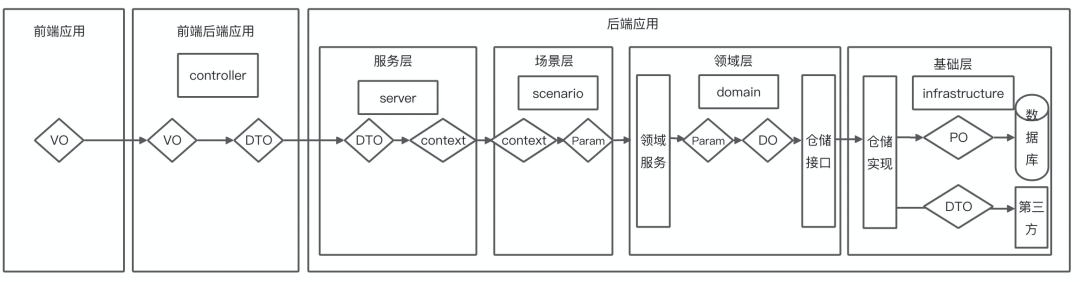
3.3 调用链路
四、DDD的基本概念
4.1 领域模型
领域(战略):业务范围,范围就是边界。
子领域:领域可大可小,我们将一个领域进行拆解形成子领域,子领域还可以进行拆解。当一个领域太大的时候需要进行细化拆解。
模型(战术):基于某个业务领域识别出这个业务领域的聚合,聚合根,界限上下文,实体,值对象。
4.2 限界上下文(战略)
4.3 实体(ENTITY)
4.4 值对象(VALUEOBJECT)


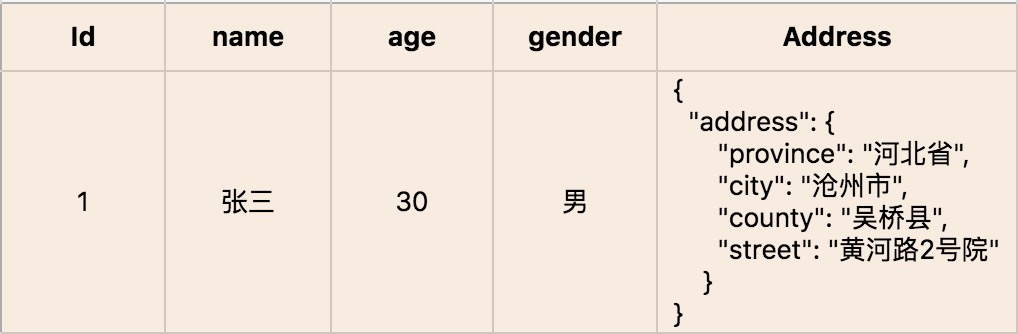
简化数据库设计,提升数据库操作的性能(多表新增和修改,关联表查询)。
虽然简化数据库设计,但是领域模型还是可以表达业务。
序列化的方式会使搜索实现困难(通过搜索引擎可以解决)。
4.5 聚合和聚合根
4.6 限界上下文,域,聚合,实体,值对象的关系
4.7 事件风暴
五、如何建模
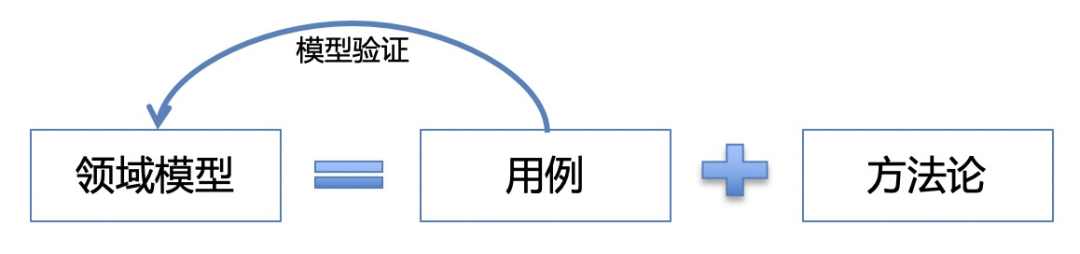
用例场景梳理:就是一句话需求,但我们需要把一些模糊的概念通过对话的方式逐步得到明确的需求,在加以提炼和抽象。
建模方法论:词法分析(找名词和动词),领域边界
模型验证
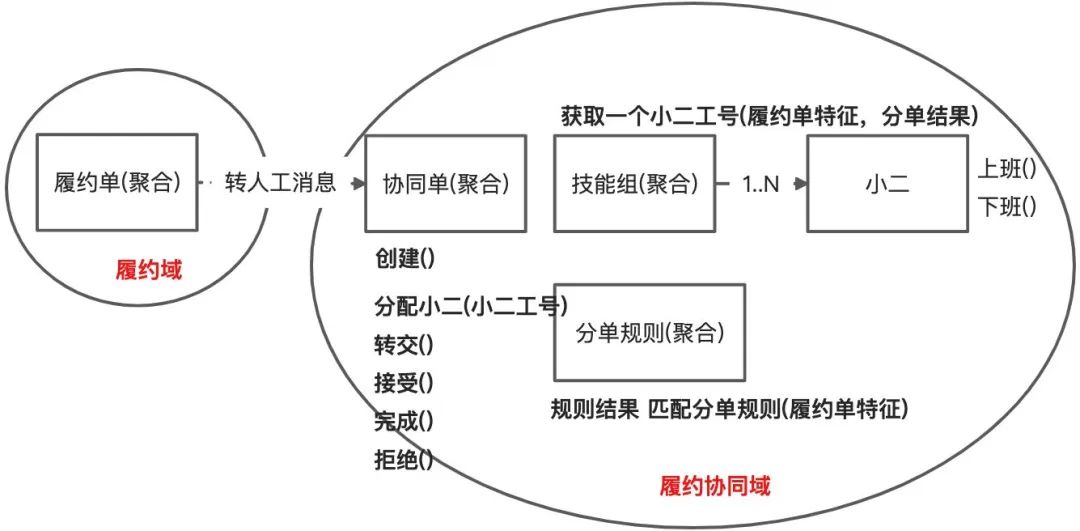
5.1 协同单自动化分单案例
产品小A:把需求读了一遍.......。
开发小B:那就是将履约单分配给个小二对吧?
产品小A:不对,我们还需要根据一个规则自动分单,例如退票订单分给退票的小二
开发小B:恩,那我们可以做一个分单规则管理。例如:新增一个退票分单规则,在里面添加一批小二工号。履约单基于自身属性去匹配分单规则并找到一个规则,然后从分单规则里面选择一个小二工号,履约单写入小二工号即可。
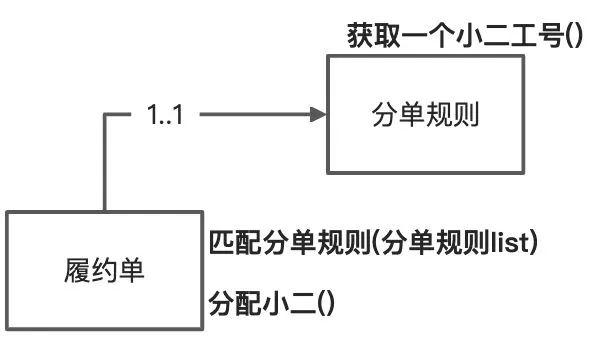
产品小A:分单规则还需要有优先级,其中小二如果上班了才分配,如果下班了就不分配。
开发小B:优先级没有问题,在匹配分单规则方法里面按照优先级排序即可,不影响模型。而小二就不是简单一个工号维护在分单规则中,小二有状态了。
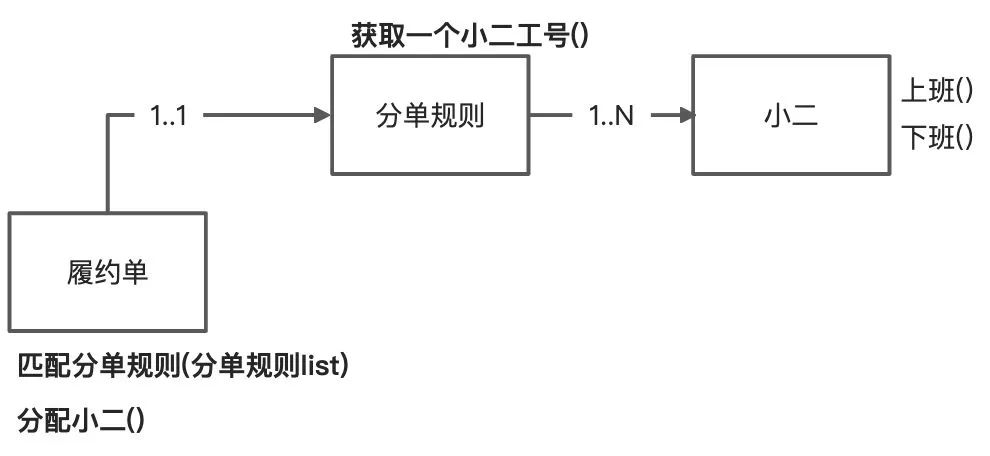
产品小A:分单规则里面添加小二操作太麻烦了,例如:每次新增一个规则都要去挑人,人也不一定记得住,实际客服在管理小二的时候是按照技能组管理的。
开发小B:恩,懂了,那就是通过新增一个技能组管理模块来管理小二。然后在通过分单规则来配置1个技能组即可。获取一个小二工号就在技能组里面了。
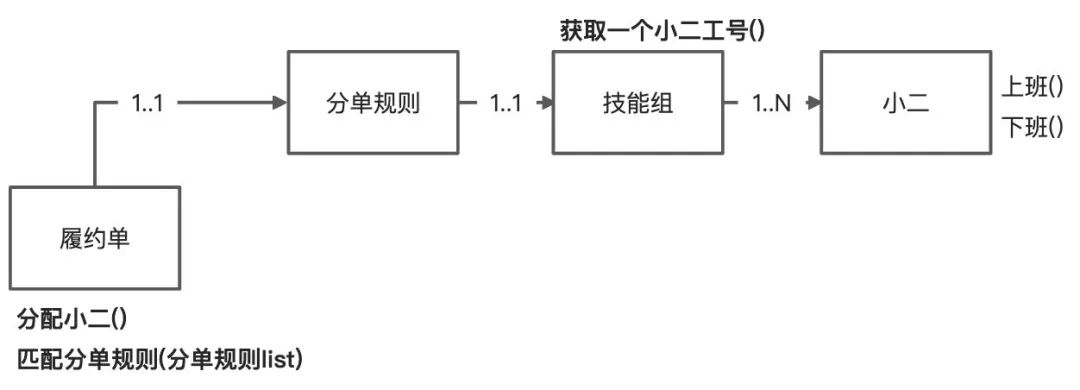
开发小B:总感觉不对,因为新增一个自动化分单需求,履约单就依赖了分单规则,履约单应该是一个独立的域,分单不是履约的能力,履约单实际只需要知道处理人是谁,至于怎么分配的他不太关心。应该由分单规则基于履约单属性找匹配一个规则,然后基于这个规则找到一个小二。履约单与分单逻辑解耦。
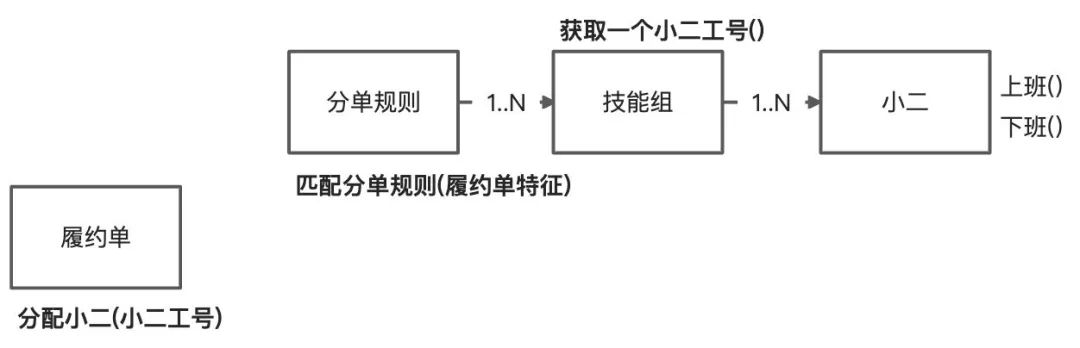
产品小A:分单要轮流分配或者能者多劳分配,小二之前处理过的订单和航司优先分配。
开发小B:获取小二的逻辑越来越复杂了,实际技能组才是找小二的核心,分单规则核心是通过履约单特征得到一个规则结果(技能组ID,分单策略,特征规则)。技能组基于分单规则的结果获得小二工号。

产品小A:还漏了一个信息,就是履约单会被多次分配的情况,每一个履约环节都可能转人工,客服需要知道履约单被处理多次的情况
开发小B:那用履约单无法表达了,我们需要新增一个概念叫协同单,协同单是为了协同履约单,通过协同推进履约单的进度。
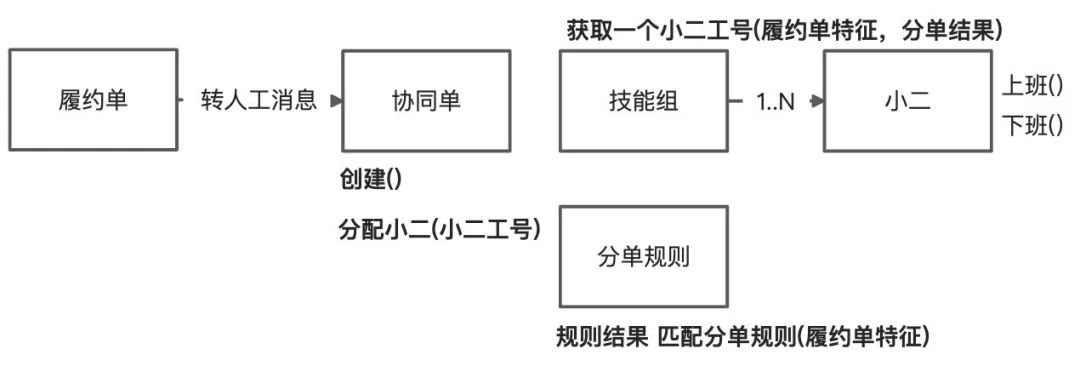
产品小A:协同单概念很好,小二下班后,如果没有处理完,还可以转交给别人。
开发小B:恩,那只需要在协同单上增加行为即可。
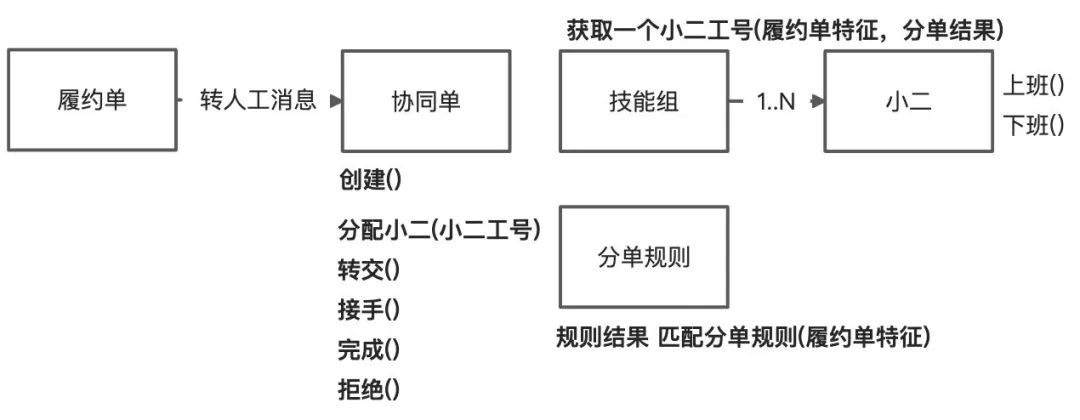
左滑查看

六、怎么写代码
6.1 DDD规范

application:CRQS模式,ApplicationCmdService是command,ApplicationQueryService是query
service:是领域服务规范,其中定义了DomainService,应用系统需要继承它。
model:是聚合根,实体,值对象的规范。
Aggregate和BaseAggregate:聚合根定义
Entity和BaseEntity:实体定义
Value和BaseValue:值对象定义
Param和BaseParam:领域层参数定义,用作域服务,聚合根和实体的方法参数
Lazy:描述聚合根属性是延迟加载属性,类似与hibernate。
Field:实体属性,用来实现update-tracing
/*** 实体属性,update-tracing* @param <T>*/public final class Field<T> implements Changeable {private boolean changed = false;private T value;private Field(T value){this.value = value;}public void setValue(T value){if(!equalsValue(value)){this.changed = true;}this.value = value;}public boolean isChanged() {return changed;}public T getValue() {return value;}public boolean equalsValue(T value){if(this.value == null && value == null){return true;}if(this.value == null){return false;}if(value == null){return false;}return this.value.equals(value);}public static <T> Field<T> build(T value){return new Field<T>(value);}}
repository Repository:仓库定义 AggregateRepository:聚合根仓库,定义聚合根常用的存储和查询方法 event:事件处理 exception:定义了不同层用的异常 AggregateException:聚合根里面抛的异常 RepositoryException:基础层抛的异常 EventProcessException:事件处理抛的
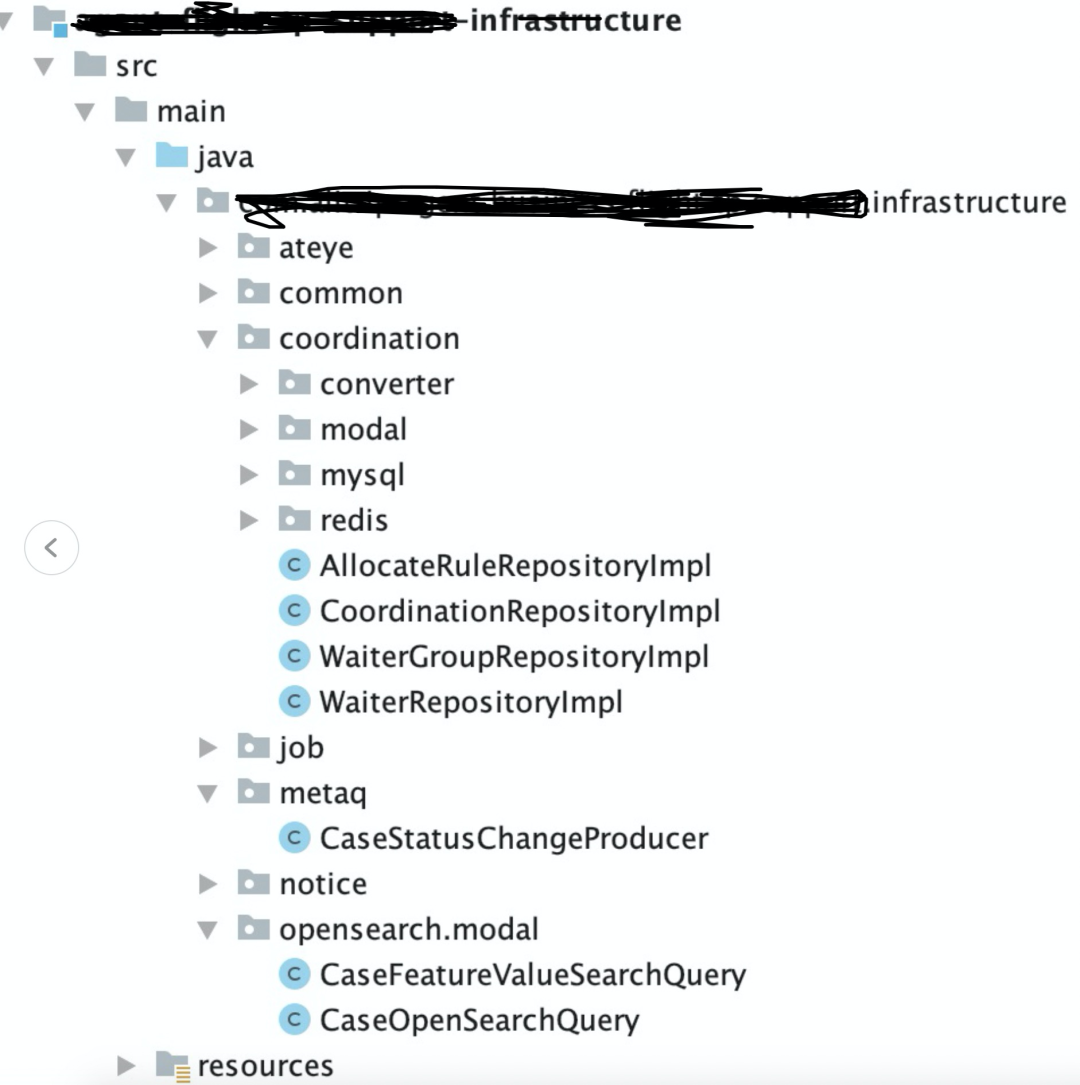
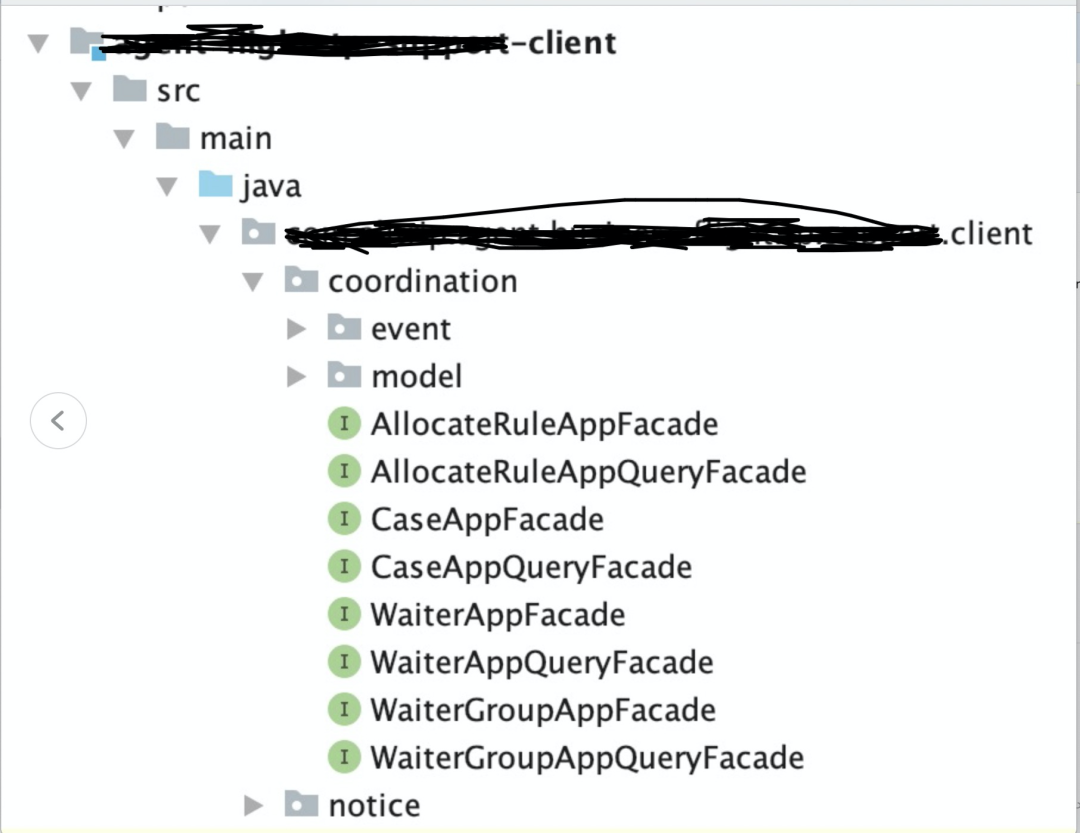
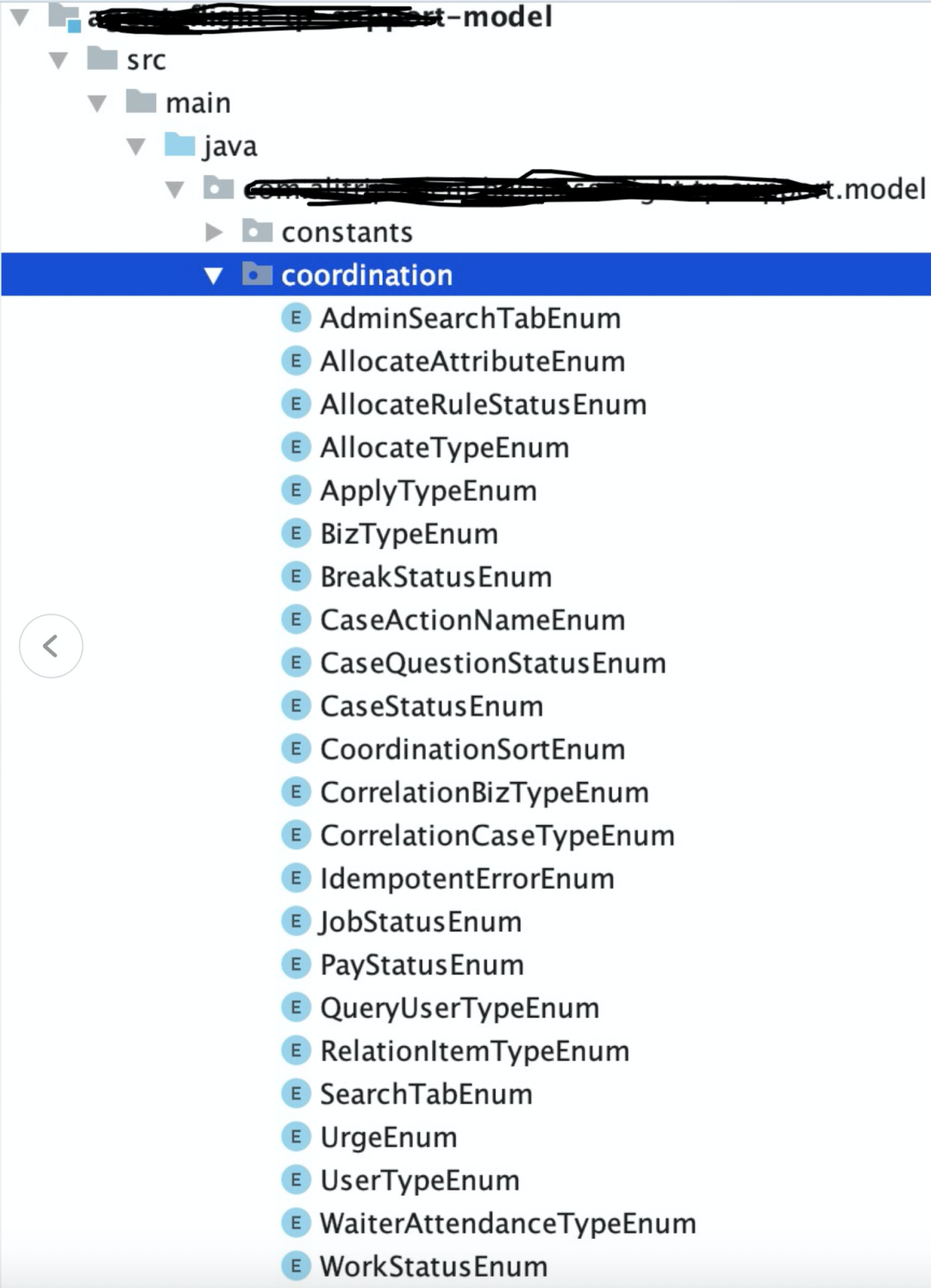
6.2 工程结构

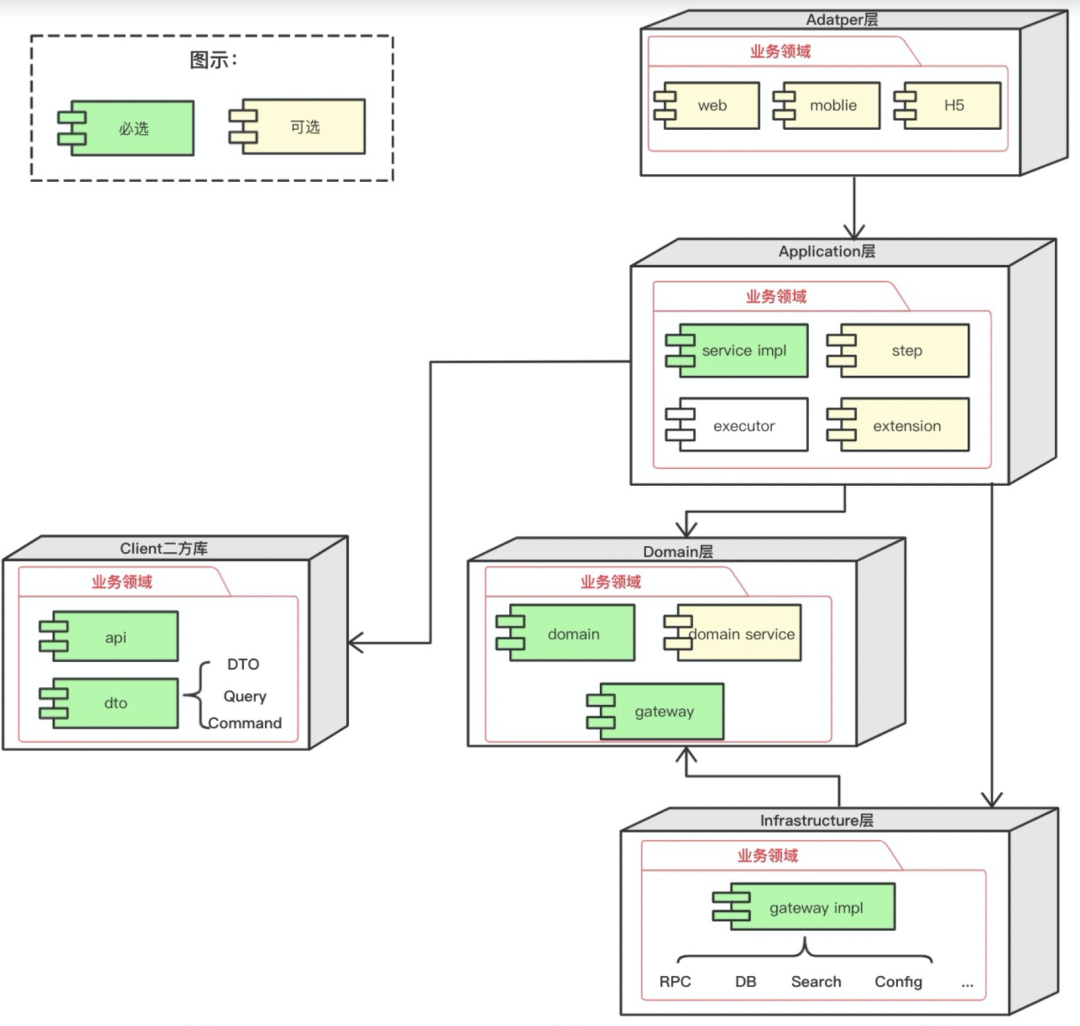
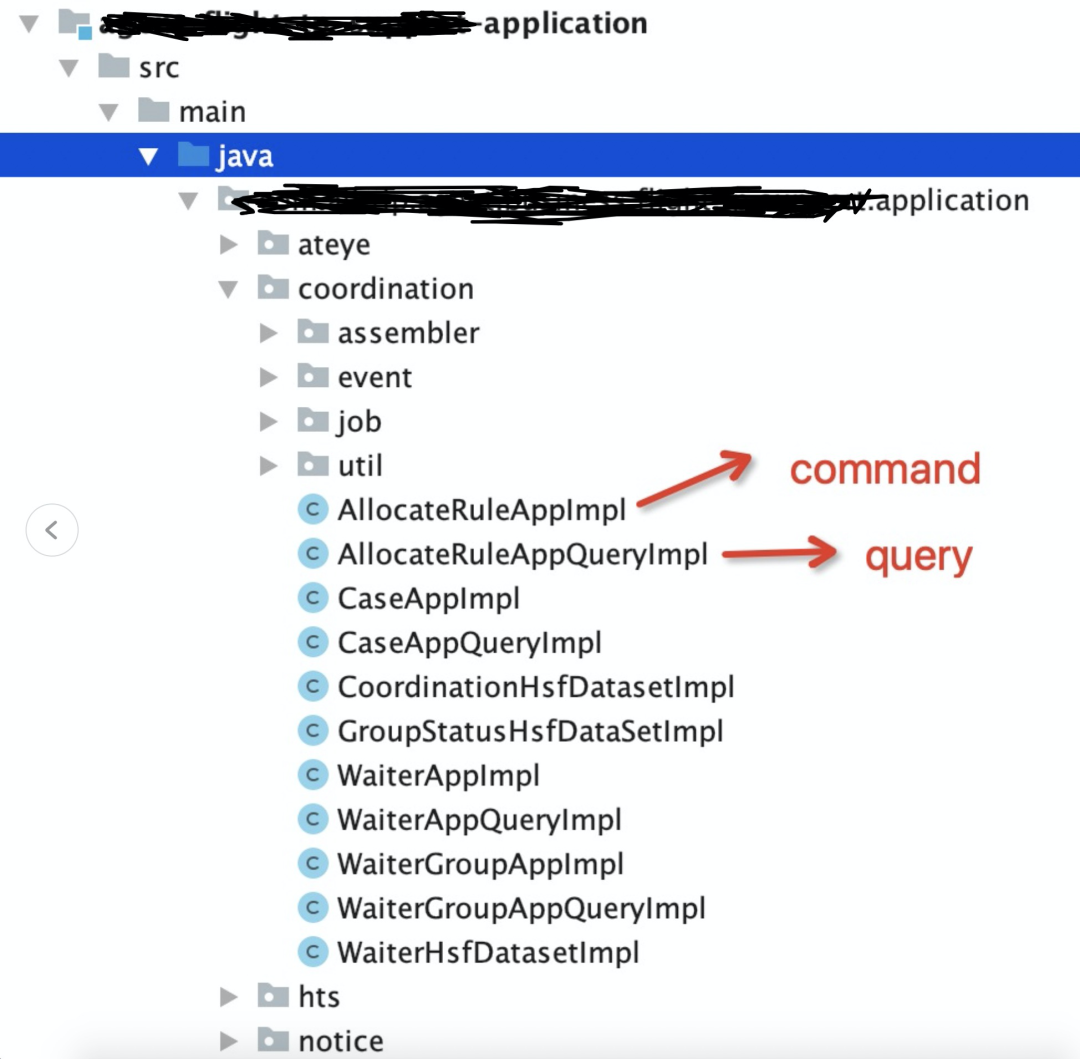
CRQS模式:commad和query分离。
重点做跨域的编排工作,无业务逻辑。
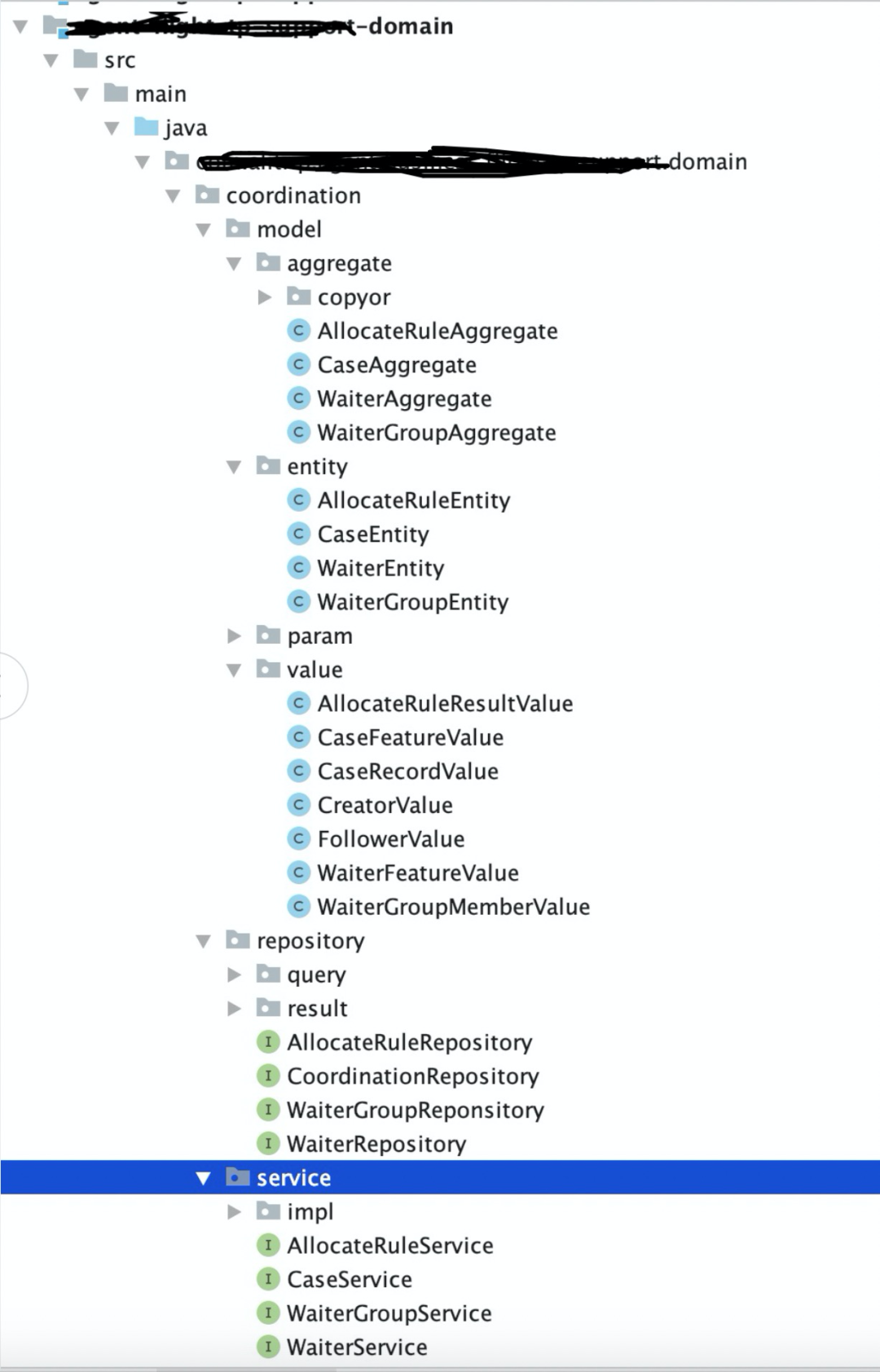
域服务,聚合根,值对象,领域参数,仓库定义
6.3 代码示例
public interface CaseAppFacade extends ApplicationCmdService {/*** 接手协同单* @param handleCaseDto* @return*/ResultDO<Void> handle(HandleCaseDto handleCaseDto);}public class CaseAppImpl implements CaseAppFacade {private CaseService caseService;//域服务CaseAssembler caseAssembler;//DTO转Parampublic ResultDO<Void> handle(HandleCaseDto handleCaseDto) {try {ResultDO<Void> resultDO = caseService.handle(caseAssembler.from(handleCaseDto));if (resultDO.isSuccess()) {pushMsg(handleCaseDto.getId());return ResultDO.buildSuccessResult(null);}return ResultDO.buildFailResult(resultDO.getMsg());} catch (Exception e) {return ResultDO.buildFailResult(e.getMessage());}}}
mapstruct:VO,DTO,PARAM,DO,PO转换非常方便,代码量大大减少。 CaseAppImpl.handle调用域服务caseService.handle。
public interface CaseService extends DomainService {/*** 接手协同单** @param handleParam* @return*/ResultDO<Void> handle(HandleParam handleParam);}public class CaseServiceImpl implements CaseService {private CoordinationRepository coordinationRepository;public ResultDO<Void> handle(HandleParam handleParam) {SyncLock lock = null;try {lock = coordinationRepository.syncLock(handleParam.getId().toString());if (null == lock) {return ResultDO.buildFailResult("协同单handle加锁失败");}CaseAggregate caseAggregate = coordinationRepository.query(handleParam.getId());caseAggregate.handle(handleParam.getFollowerValue());coordinationRepository.save(caseAggregate);return ResultDO.buildSuccessResult(null);} catch (RepositoryException | AggregateException e) {String msg = LOG.error4Tracer(OpLogConstant.traceId(handleParam.getId()), e, "协同单handle异常");return ResultDO.buildFailResult(msg);} finally {if (null != lock) {coordinationRepository.unlock(lock);}}}}
领域层不依赖基础层的实现:coordinationRepository只是接口,在领域层定义好,由基础层依赖领域层实现这个接口。
业务逻辑和技术解耦:域服务这层通过调用coordinationRepository和聚合根将业务逻辑和技术解耦。
聚合根的方法无副作用:聚合根的方法只对聚合根内部实体属性的改变,不做持久化动作,可反复测试。
模型与数据分离:
改变模型:caseAggregate.handle(handleParam.getFollowerValue())。
改变数据:coordinationRepository.save(caseAggregate);事务是在save方法上。
public class CaseAggregate extends BaseAggregate implements NoticeMsgBuilder {private final CaseEntity caseEntity;public CaseAggregate(CaseEntity caseEntity) {this.caseEntity = caseEntity;}/*** 接手协同单* @param followerValue* @return*/public void handle(FollowerValue followerValue) throws AggregateException {try {this.caseEntity.handle(followerValue);} catch (Exception e) {throw e;}}}public class CaseEntity extends BaseEntity {/*** 创建时间*/private Field<Date> gmtCreate;/*** 修改时间*/private Field<Date> gmtModified;/*** 问题分类*/private Field<Long> caseType;/*** 是否需要支付*/private Field<Boolean> needPayFlag;/*** 是否需要自动验收通过协同单*/private Field<Integer> autoAcceptCoordinationFlag;/*** 发起协同人值对象*/private Field<CreatorValue> creatorValue;/*** 跟进人*/private Field<FollowerValue> followerValue;/*** 状态*/private Field<CaseStatusEnum> status;/*** 关联协同单id*/private Field<String> relatedCaseId;/*** 关联协同单类型* @see 读配置 com.alitrip.agent.business.flight.common.model.dataobject.CoordinationCaseTypeDO*/private Field<String> relatedBizType;/*** 支付状态*/private Field<PayStatusEnum> payStatus;省略....public CaseFeatureValue getCaseFeatureValue() {return get(caseFeatureValue);}public Boolean isCaseFeatureValueChanged() {return caseFeatureValue.isChanged();}public void setCaseFeatureValue(CaseFeatureValue caseFeatureValue) {this.caseFeatureValue = set(this.caseFeatureValue, caseFeatureValue);}public Boolean isPayStatusChanged() {return payStatus.isChanged();}public Boolean isGmtCreateChanged() {return gmtCreate.isChanged();}public Boolean isGmtModifiedChanged() {return gmtModified.isChanged();}public Boolean isCaseTypeChanged() {return caseType.isChanged();}省略..../*** 接手*/public void handle(FollowerValue followerValue) throws AggregateException {if (isWaitProcess()||isAppointProcess()) {this.setFollowerValue(followerValue);this.setStatus(CaseStatusEnum.PROCESSING);this.setGmtModified(new Date());initCaseRecordValue(CaseActionNameEnum.HANDLE, null, followerValue);} else {throwStatusAggregateException();}}省略....}
充血模型VS贫血模型:
充血模型:表达能力强,代码高内聚,领域内封闭,聚合根内部结构对外不可见,通过聚合根的方法访问,适合复杂企业业务逻辑。
贫血模型:业务复杂之后,逻辑散落到大量方法中。
规范大于技巧:DDD架构可以避免引入一些其他概念,系统只有域,域服务,聚合根,实体,值对象,事件来构建系统。



聚合根和实体定义的方法是具备单一原则,复用性原则与使用场景无关,例如:不能定义手工创建协调单和系统自动创建协同单,应该定义创建协同单。
Update-tracing:handle方法修改属性后,然后调用 coordinationRepository.save(caseAggregate),我们只能全量属性更新。Update-tracing是监控实体的变更。Entiy定义属性通过Field进行包装实现属性的变更状态记录,结合mapstruct转换PO实现Update-tracing。

if(caseEntity.isAppended() || caseEntity.isCaseTypeChanged()){casePO.setCaseType( caseEntity.getCaseType() );}
当属性被改变后就转换到po中,这样就可以实现修改后的字段更新。
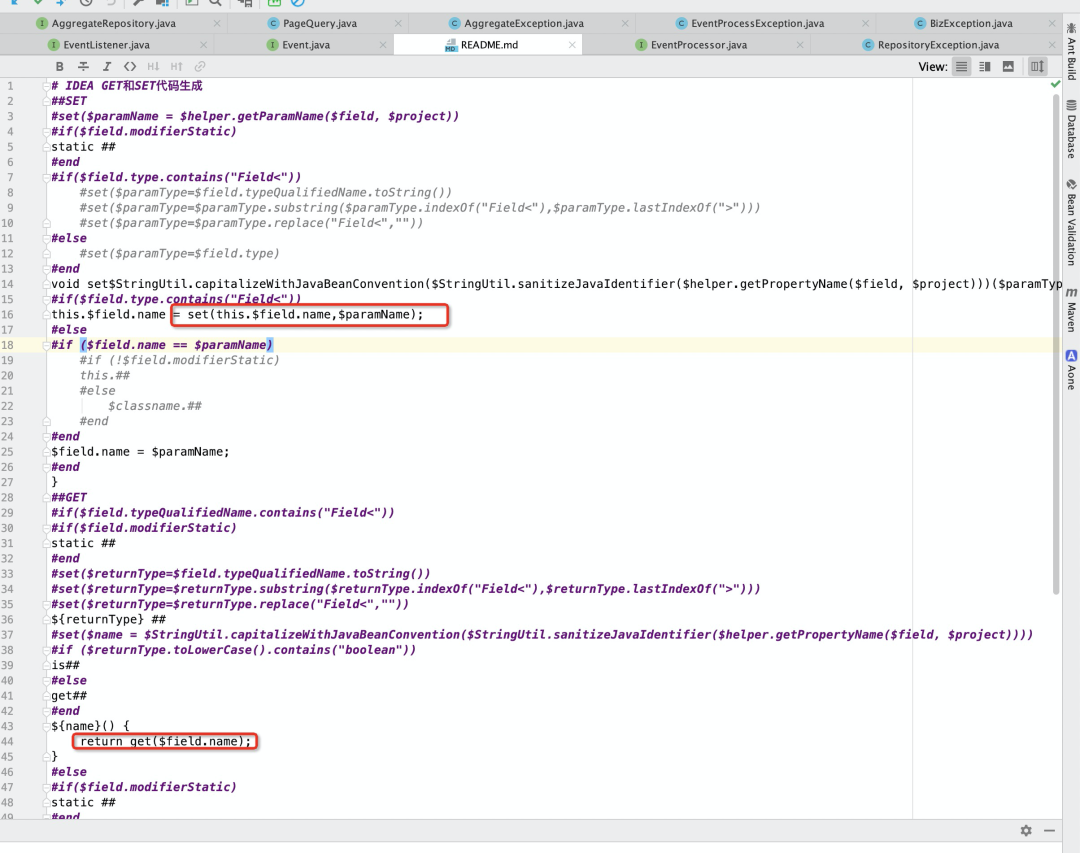
idea的get和set方法自动生成:由于使用field包装,需要自定义get和set生成代码。
public interface CoordinationRepository extends Repository {/*** 保存/更新* @param aggregate* @throws RepositoryException*/void save(CaseAggregate aggregate) throws RepositoryException;}@Repositorypublic class CoordinationRepositoryImpl implements CoordinationRepository {@Overridepublic void save(CaseAggregate aggregate) throws RepositoryException {try {//聚合根转PO,update-tracing技术CasePO casePO = caseConverter.toCasePO(aggregate.getCase());CasePO oldCasePO = null;if (aggregate.getCase().isAppended()) {casePOMapper.insert(casePO);aggregate.getCase().setId(casePO.getId());} else {oldCasePO = casePOMapper.selectByPrimaryKey(casePO.getId());casePOMapper.updateByPrimaryKeySelective(casePO);}// 发送协同单状态改变消息if (CaseStatusEnum.FINISH.getCode().equals(casePO.getStatus())|| CaseStatusEnum.WAIT_DISTRIBUTION.getCode().equals(casePO.getStatus())|| CaseStatusEnum.PROCESSING.getCode().equals(casePO.getStatus())|| CaseStatusEnum.APPOINT_PROCESS.getCode().equals(casePO.getStatus())|| CaseStatusEnum.WAIT_PROCESS.getCode().equals(casePO.getStatus())|| CaseStatusEnum.CLOSE.getCode().equals(casePO.getStatus())|| CaseStatusEnum.REJECT.getCode().equals(casePO.getStatus())|| CaseStatusEnum.PENDING_ACCEPTANCE.getCode().equals(casePO.getStatus())) {FollowerDto followerDto = new FollowerDto();followerDto.setCurrentFollowerId(aggregate.getCase().getFollowerValue().getCurrentFollowerId());followerDto.setCurrentFollowerGroupId(aggregate.getCase().getFollowerValue().getCurrentFollowerGroupId());followerDto.setCurrentFollowerType(aggregate.getCase().getFollowerValue().getCurrentFollowerType());followerDto.setCurrentFollowerName(aggregate.getCase().getFollowerValue().getCurrentFollowerName());//拒绝和关闭都使用CLOSEString tag = CaseStatusEnum.codeOf(casePO.getStatus()).name();if(CaseStatusEnum.REJECT.name().equals(tag)){tag = CaseStatusEnum.CLOSE.name();}statusChangeProducer.send(CaseStatusChangeEvent.build().setId(casePO.getId()).setFollowerDto(followerDto).setStatus(aggregate.getCase().getStatus().getCode()).setCaseType(aggregate.getCase().getCaseType()).setOldStatus(null != oldCasePO ? oldCasePO.getStatus() : null).setAppointTime(aggregate.getCase().getAppointTime()), (tag));}// 操作日志if (CollectionUtils.isNotEmpty(aggregate.getCase().getCaseRecordValue())) {CaseRecordValue caseRecordValue = Lists.newArrayList(aggregate.getCase().getCaseRecordValue()).get(0);caseRecordValue.setCaseId(casePO.getId());recordPOMapper.insert(caseConverter.from(caseRecordValue));}} catch (Exception e) {throw new RepositoryException("", e.getMessage(), e);}}}
CoordinationRepository接口定义在领域层。 CoordinationRepositoryImpl实现在基础层:数据库操作都是基于聚合根操作,保证聚合根里面的实体强一致性。
最后结束语

