Python爬虫一个requests_html模块足矣!(支持JS加载&异步请求)
52xiaoqiangclub2021-05-30 09:00
安装
基本使用
发送请求
解析响应获
获取需要的内容
快速获取链接
获取元素
高级功能
JS渲染
自动翻页(不太好用)
异步
异步渲染JS
异步发送请求
初识requests_html模块
感觉只要学过Python爬虫的同学应该都知道requests这个库吧,它在我们的Python爬虫任务中应该是最常用的一个库了!今天跟大家分享的这个模块requests_html,他的作者和前者是同一人!这是一个解析HTML的库,用起来和requests一样方便,下面就来介绍一下它!
使用requests_html
安装
依然是那个命令 pip3 install -i https://pypi.doubanio.com/simple requests_html注意:由于 requests_html模块中使用了异步asynico模块,所以官方声明,需要在python3.6以上版本才能正常使用!
基本使用
发送请求
requests_html发送请求获取页面需要先实例化一个HTMLSession对象,然后使用get/post...方法获取响应,如下列代码
#!/usr/bin/env python3
# coding : utf-8
# Author : xiao qiang
# Software : PyCharm
# File : test.py
# Time : 2021/5/29 7:57
from requests_html import HTMLSession
if __name__ == '__main__':
url = 'https://wwww.baidu.com'
session = HTMLSession() # 获取实例化session对象
r = session.get(url) # 这里的请求和requests的几乎一样!同样可以根据需要添加headers等参数
requests_html发送请求的方式和requests中使用session方式发送请求几乎是一样的,可以对比参考requests_html同样可以发送get/post等请求,且可以和requests同样携带headers/data等参数,具体用法参考requests
解析响应获
接上,我们需要将获取的响应解析获取 html页面,在这里我们同样可以使用requests中的r.content.decode()等原方法!但是在 requests_html中还提供了更便捷的方法:r.html.htmlr.html.html实际上是使用了requests_html中的HTML类(负责对HTML进行解析)来进行解析!如下
#!/usr/bin/env python3
# coding : utf-8
# Author : xiao qiang
# Software : PyCharm
# File : test.py
# Time : 2021/5/29 7:57
from requests_html import HTMLSession
if __name__ == '__main__':
url = 'https://wwww.baidu.com'
session = HTMLSession() # 获取实例化session对象
r = session.get(url) # 这里的请求和requests的几乎一样!同样可以根据需要添加headers等参数
# 获取html页面
# html = r.content.decode() # requests方式
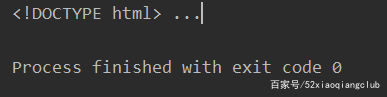
get_html = r.html.html # requests_html中的方法
print(get_html[:15], '...')
运行结果(这里只显示了部分结果!)
获取需要的内容
快速获取链接
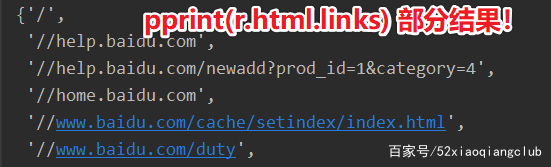
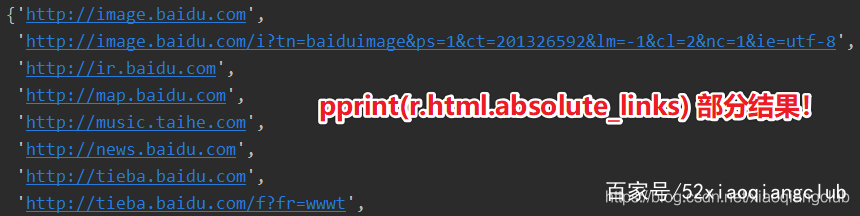
在 requests_html中提供了快速获取网址链接的方法使用 links和absolute_links两个属性分别可以返回HTML对象所包含的所有链接和绝对链接(均不包含锚点)
# 快速获取链接
pprint(r.html.links) # 获取html中的链接(href属性)
pprint(r.html.absolute_links) # 会自动拼接url生成绝对链接
部分运行结果如下
获取元素
requests_html中的HTML对象可以直接使用xpath和css选择器
使用xpath
requests_html中的HTML对象支持xpath语法,它有以下几个参数:
def xpath(self, selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None) -> _XPath:
- selector,要用的 xpath选择器;
- clean,布尔值,如果为True,会清除HTML中style和script标签;
- first,布尔值,如果为True,会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
接上面的例子!使用获取到的响应得到 HTML对象:r.html
pprint(r.html.xpath('//li[@class="hotsearch-item odd"]/a'))
pprint(r.html.xpath('//li[@class="hotsearch-item odd"]/a', first=True).text)
运行结果

xpath语法
使用css选择器(find方法)
requests_html中的HTML对象支持css选择器,它有以下几个参数:
def find(self, selector: str = "*", *, containing: _Containing = None, clean: bool = False, first: bool = False, _encoding: str = None) -> _Find:
- selector,要用的CSS选择器;
- clean,布尔值,如果为True,会清除HTML中style和script标签;
- containing,如果设置该属性,只返回包含该属性文本的标签;
- first,布尔值,如果为True,会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
接上面的例子!使用获取到的响应得到 HTML对象:r.html
pprint(r.html.find('a.mnav'))
pprint(r.html.find('a.mnav', first=True).text)
运行结果
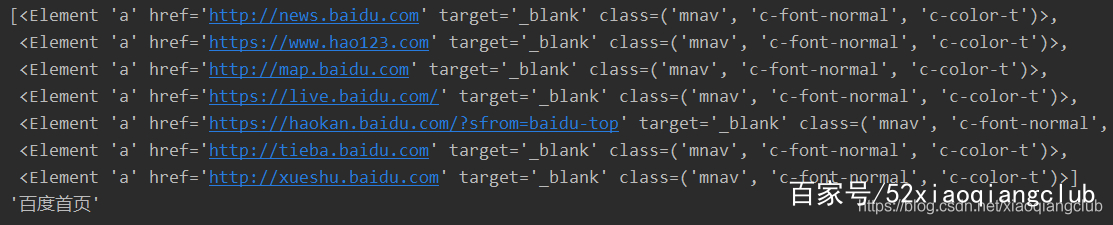
css选择器语法 可以使用 text属性来获取元素的文本内容
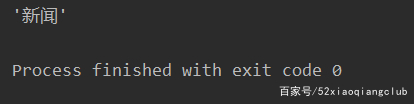
pprint(r.html.find('a.mnav')[0].text)
执行结果
如果要获取元素的
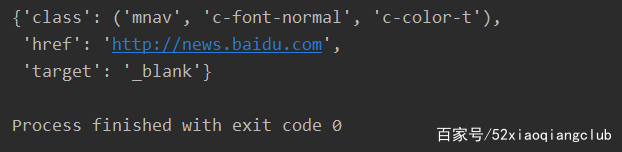
attribute,用attrs属性:
pprint(r.html.find('a.mnav')[0].attrs)
执行结果
获取到 attrs属性后,就可以使用字典的相关方法获取内容了!最后还可以使用 html属性获取一个元素的html代码,如下
pprint(r.html.find('a.mnav')[0].html)
执行结果

搜索(search、search_all)
requests_html除了上面的方式还可以使用search/search_all来直接搜索内容!
def search(self, template: str) -> Result:
# 只有一个参数
template: 就是要检索的内容,这里使用英文状态的 {} 来获取内容,有点类似正则里面的 ()
使用英文状态的 {} 来获取内容,如下
ret = r.html.find('a.mnav')[0].search('新{}')
pprint(ret)
pprint(type(ret))
pprint(ret[0])
执行结果

search()获取到的是第一个匹配的对象,而searchh_all()则是获取所有匹配的对象,得到的是一个列表,如下
ret = r.html.find('a.mnav')[0].search_all('新{}')
pprint(ret)
pprint(type(ret))
pprint(ret[0][0])
运行结果

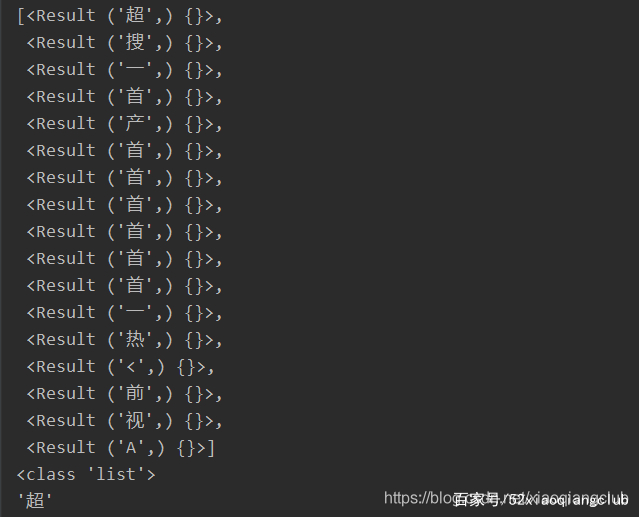
除了对某个元素进行检索外,还可以直接对 html对象进行搜索,如下
ret = r.html.search_all('百度{}')
pprint(ret)
pprint(type(ret))
pprint(ret[0][0])
运行结果
requests_html内容提取的方式这么多,大家可以根据需要和习惯选择使用!
HTML类
requests_html中使用HTML类负责对HTML进行解析HTML类不仅可以解析网络请求获取的响应,还可以直接解析html文本,如下
>>> from requests_html import HTML
>>> doc = """<a href='https://www.baidu.com'>"""
>>> html = HTML(html=doc)
>>> html.links
{'https://www.baidu.com'}
还可以直接 渲染JS,如下
# 和上面一段代码接起来
>>> script = """
() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}
"""
>>> val = html.render(script=script, reload=False) # render()方法 后面会讲
>>> print(val)
{'width': 800, 'height': 600, 'deviceScaleFactor': 1}
>>> print(html.html)
<html><head></head><body><a href="https://www.baidu.com"></a></body></html>
高级功能
前面介绍的是 requests_html在requests库的基础上整合的html解析&数据筛选的功能!下面要为大家介绍的是 requests_html模块中的一些高级功能:自动渲染JS&智能分页
JS渲染
我们在做爬虫项目的时候会遇到网站的 页面是由js生成的情况!这个时候要么就是自己去一步一步的分析请求,要么就是使用selenium等第三方库来进行渲染页面,为了解决这个难题,requests_html模块中引进了pyppeteer,使用pyppeteer可以像使用selenium一样实现网站的完整加载!而且pyppeteer是一个异步模块!效率会更高!requests_html模块在HTML对象的基础上使用render()方法来重新加载js页面注意:在第一次使用 render()的时候,系统在用户目录(默认是~/.pyppeteer/)中下载一个chromium。下载过程只在第一次执行,以后就可以直接使用chromium来执行任务了。在没有科学上网的环境下可能下载速度有点慢,请耐心等待...下面是一个官方示例
>>> r = session.get('http://python-requests.org/')
>>> r.html.render()
[W:pyppeteer.chromium_downloader] start chromium download.
Download may take a few minutes.
[W:pyppeteer.chromium_downloader] chromium download done.
[W:pyppeteer.chromium_downloader] chromium extracted to: C:\Users\xxxx\.pyppeteer\local-chromium\571375
>>> r.html.search('Python 2 will retire in only {months} months!')['months']
'<time>25</time>'
requests_html模块在HTML对象的基础上使用render()方法来重新加载js页面,它有以下几个参数:
def render(self, retries: int = 8, script: str = None, wait: float = 0.2, scrolldown=False, sleep: int = 0, reload: bool = True, timeout: Union[float, int] = 8.0, keep_page: bool = False):
- retries: 加载页面失败的次数
- script: 页面上需要执行的JS脚本(可选)
- wait: 加载页面前等待的时间(秒),防止超时(可选)
- scrolldown: 页面向下滚动的次数(整数)
- sleep: 在页面初次渲染之后的等待时间
- reload: 如果为False,那么页面不会从浏览器中加载,而是从内存中加载,只有设置为True才会在浏览器中渲染JS
- keep_page: 如果为True,允许您使用 r.html.page 访问浏览器页面
requests_html还支持异步渲染JS[^1]
自动翻页(不太好用)
很多网站会出现翻页的情况, requests_html模块的HTML对象中提供了一个next()方法来实现自动翻页!requests_html模块在HTML对象的基础上使用next()方法来实现自动翻页!,它有以下几个参数:
def next(self, fetch: bool = False, next_symbol: _NextSymbol = DEFAULT_NEXT_SYMBOL) -> _Next:
fetch: 一个布尔型参数,默认为False:直接返回下一页的 url地址;
如果设置为True:则直接返回下一页的 HTML对象
这个方法我自己测试了一下,只有一些特定的网站才能实现这个功能, requests_html在的源码中可以看到,作者通过搜索包含'next', 'more', 'older'字段的a标签(因为一般情况下我们的下一页url就是在a标签下的href属性中),所以只有满足了他的条件才会实现这个功能(也就是说HTML页面不按照这个套路它就无法实现这个功能!),下面是部分源码
DEFAULT_NEXT_SYMBOL = ['next', 'more', 'older']
# next()方法
def next(self, fetch: bool = False, next_symbol: _NextSymbol = DEFAULT_NEXT_SYMBOL) -> _Next:
"""Attempts to find the next page, if there is one. If ``fetch``
is ``True`` (default), returns :class:`HTML <HTML>` object of
next page. If ``fetch`` is ``False``, simply returns the next URL.
"""
def get_next():
candidates = self.find('a', containing=next_symbol) # 寻找 包含字段'next', 'more', 'older' 的a标签
这里我就不做举例了,大家可以自行去尝试!
异步
requests_html中还支持了异步功能requests_html是使用了asynico来封装了一些异步操作,所以这里的一些操作会用到asynico库相关的一些知识,如果您还不太了解,请自行学习!
异步渲染JS
前面我们介绍了使用 render()方法渲染JS,其实它还支持异步渲染一般 异步渲染使用在我们有多个页面需要进行渲染的情况下,因为只要在多任务的时候才能体现出异步的高效率,下面是一个官方示例
>>> async def get_pyclock():
... r = await asession.get('https://pythonclock.org/')
... await r.html.arender()
... return r
...
>>> results = asession.run(get_pyclock, get_pyclock, get_pyclock) # 这里作者将同一个页面使用异步方式进行了3次渲染,但是实际上使用的时间并不是平时的3倍!可能只是比平时渲染一个页面多花了一点时间而已!这就是异步的好处!
异步发送请求
我们在做爬虫的时候,特别是大型爬虫的时候,需要对很多页面进行操作,或者说是需要发送很多请求,也就是需要进行很多 IO操作。所以,使用异步发送请求能显著的提升我们的爬虫效率!在 requests_html模块中,设置了一个AsyncHTMLSession类来实现发送异步请求,下面是一个官方示例
>>> from requests_html import AsyncHTMLSession
>>> asession = AsyncHTMLSession()
>>> async def get_pythonorg():
... r = await asession.get('https://python.org/')
... return r
...
>>> async def get_reddit():
... r = await asession.get('https://reddit.com/')
... return r
...
>>> async def get_google():
... r = await asession.get('https://google.com/')
... return r
...
>>> results = asession.run(get_pythonorg, get_reddit, get_google)
>>> results # check the requests all returned a 200 (success) code
[<Response [200]>, <Response [200]>, <Response [200]>]
>>> # Each item in the results list is a response object and can be interacted with as such
>>> for result in results:
... print(result.html.url)
...
https://www.python.org/
https://www.google.com/
https://www.reddit.com/
上面的示例用到了 asynico库中一些相关的知识,如果您还不太了解,请自行学习!
总结
requests_html模块在requests库的基础上封装了页面解析和数据清理的功能,并且添加了对当前比较流行的异步操作,让我们在做爬虫项目(一般项目)的时候无需再去使用多个第三方模块来实现功能,几乎是提供了一站式的服务!所以 Python写爬虫使用requests_html就对了!(当然大项目还是首选scrapy,个人愚见!)
举报/反馈

0
0
收藏
分享
