你还弄不懂的傅里叶变换,神经网络只用了30多行代码就学会了
量子位2021-06-01 15:21
明敏 发自 凹非寺 量子位 报道 | 公众号 QbitAI
在我们的生活中,大到天体观测、小到MP3播放器上的频谱,没有傅里叶变换都无法实现。
通俗来讲,离散傅里叶变换(DFT)就是把一串复杂波形中分成不同频率成分。
比如声音,如果用声波记录仪显示声音的话,其实生活中绝大部分声音都是非常复杂、甚至杂乱无章的。
而通过傅里叶变换,就能把这些杂乱的声波转化为正弦波,也就是我们平常看到的音乐频谱图的样子。

不过在实际计算中,这个过程其实非常复杂。
如果把声波视作一个连续函数,它可以唯一表示为一堆三角函数相叠加。不过在叠加过程中,每个三角函数的加权系数不同,有的要加高一些、有的要压低一些,有的甚至不加。
傅里叶变换要找到这些三角函数以及它们各自的权重。
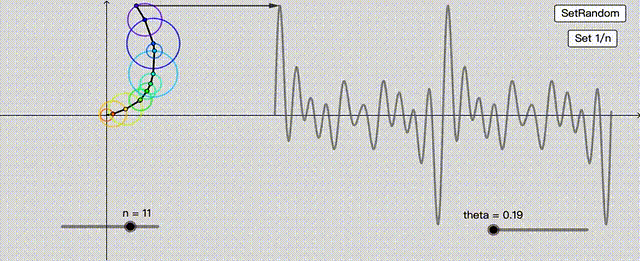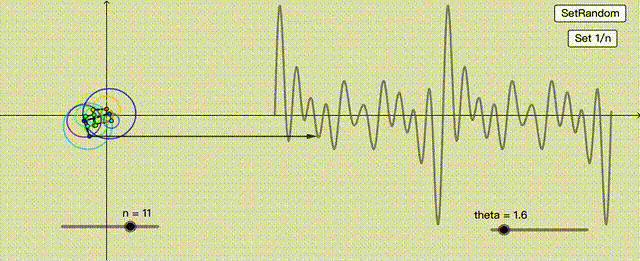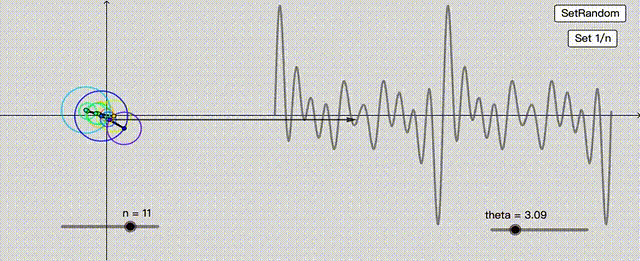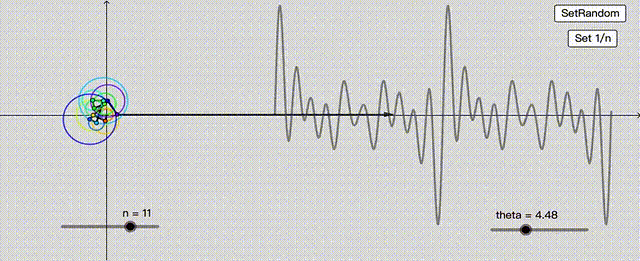
这不就巧了,这种找啊找的过程,像极了神经网络。
神经网络的本质其实就是逼近一个函数。
那岂不是可以用训练神经网络的方式来搞定傅里叶变换?
这还真的可行,并且最近有人在网上发布了自己训练的过程和结果。
DFT=神经网络
该怎么训练神经网络呢?这位网友给出的思路是这样的:
首先要把离散傅里叶变换(DFT)看作是一个人工神经网络,这是一个单层网络,没有bias、没有激活函数,并且对于权重有特定的值。它输出节点的数量等于傅里叶变换计算后频率的数量。
具体方法如下:
这是一个DFT:

k表示每N个样本的循环次数;N表示信号的长度;表示信号在样本n处的值。一个信号可以表示为所有正弦信号的和。
yk是一个复值,它给出了信号x中频率为k的正弦信号的信息;从yk我们可以计算正弦的振幅和相位。
换成矩阵式,它就变成了这样:

这里给出了特定值k的傅里叶值。
不过通常情况下,我们要计算全频谱,即k从[0,1,…N-1]的值,这可以用一个矩阵来表示(k按列递增,n按行递增):

简化后得到:

看到这里应该还很熟悉,因为它是一个没有bias和激活函数的神经网络层。
指数矩阵包含权值,可以称之为复合傅里叶权值(Complex Fourier weights),通常情况下我们并不知道神经网络的权重,不过在这里可以。
不用复数通常我们也不会在神经网络中使用复数,为了适应这种情况,就需要把矩阵的大小翻倍,使其左边部分包含实数,右边部分包含虚数。

将

带入DFT,可以得到:

然后用实部(cos形式)来表示矩阵的左半部分,用虚部(sin形式)来表示矩阵的右半部分:

简化后可以得到:

将

称为傅里叶权重;
需要注意的是,y^和y实际上包含相同的信息,但是y^
不使用复数,所以它的长度是y的两倍。
换句话说,我们可以用
或

表示振幅和相位,但是我们通常会使用

现在,就可以将傅里叶层加到网络中了。
用傅里叶权重计算傅里叶变换
现在就可以用神经网络来实现

,并用快速傅里叶变换(FFT)检查它是否正确。
import matplotlib.pyplot as plt
y_real = y[:, :signal_length]
y_imag = y[:, signal_length:]
tvals = np.arange(signal_length).reshape([-1, 1])
freqs = np.arange(signal_length).reshape([1, -1])
arg_vals = 2 * np.pi * tvals * freqs / signal_length
sinusoids = (y_real * np.cos(arg_vals) - y_imag * np.sin(arg_vals)) / signal_length
reconstructed_signal = np.sum(sinusoids, axis=1)
print('rmse:', np.sqrt(np.mean((x - reconstructed_signal)**2)))
plt.subplot(2, 1, 1)plt.plot(x[0,:])
plt.title('Original signal')
plt.subplot(2, 1, 2)
plt.plot(reconstructed_signal)
plt.title('Signal reconstructed from sinusoids after DFT')
plt.tight_layout()
plt.show()
rmse: 2.3243522568191728e-15
得到的这个微小误差值可以证明,计算的结果是我们想要的。
另一种方法是重构信号:import matplotlib.pyplot as plt
y_real = y[:, :signal_length]
y_imag = y[:, signal_length:]
tvals = np.arange(signal_length).reshape([-1, 1])
freqs = np.arange(signal_length).reshape([1, -1])
arg_vals = 2 * np.pi * tvals * freqs / signal_length
sinusoids = (y_real * np.cos(arg_vals) - y_imag * np.sin(arg_vals)) / signal_length
reconstructed_signal = np.sum(sinusoids, axis=1)
print('rmse:', np.sqrt(np.mean((x - reconstructed_signal)**2)))
plt.subplot(2, 1, 1)
plt.plot(x[0,:])
plt.title('Original signal')
plt.subplot(2, 1, 2)
plt.plot(reconstructed_signal)
plt.title('Signal reconstructed from sinusoids after DFT')
plt.tight_layout()plt.show()
rmse:2.3243522568191728e-15

最后可以看到,DFT后从正弦信号重建的信号和原始信号能够很好地重合。
通过梯度下降学习傅里叶变换
现在就到了让神经网络真正来学习的部分,这一步就不需要向之前那样预先计算权重值了。
首先,要用FFT来训练神经网络学习离散傅里叶变换:
importtensorflow as tf
signal_length = 32
# Initialise weight vector to train:
W_learned = tf.Variable(np.random.random([signal_length, 2 * signal_length]) - 0.5)
# Expected weights, for comparison:
W_expected = create_fourier_weights(signal_length)
losses = []
rmses = []
fori in range(1000):
# Generate a random signal each iteration:
x = np.random.random([1, signal_length]) - 0.5
# Compute the expected result using the FFT:
fft = np.fft.fft(x)
y_true = np.hstack([fft.real, fft.imag])
withtf.GradientTape() as tape:
y_pred = tf.matmul(x, W_learned)
loss = tf.reduce_sum(tf.square(y_pred - y_true))
# Train weights, via gradient descent:
W_gradient = tape.gradient(loss, W_learned)
W_learned = tf.Variable(W_learned - 0.1 * W_gradient)
losses.append(loss)
rmses.append(np.sqrt(np.mean((W_learned- W_expected)**2)))
Final loss value 1.6738563548424711e-09
Final weights' rmse value 3.1525832404710523e-06


得出结果如上,这证实了神经网络确实能够学习离散傅里叶变换。
训练网络学习DFT
除了用快速傅里叶变化的方法,还可以通过网络来重建输入信号来学习DFT。(类似于autoencoders自编码器)。
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning)。
W_learned = tf.Variable(np.random.random([signal_length, 2 * signal_length]) - 0.5)
tvals = np.arange(signal_length).reshape([-1, 1])
freqs = np.arange(signal_length).reshape([1, -1])
arg_vals = 2 * np.pi * tvals * freqs / signal_lengthcos_vals = tf.
cos(arg_vals) / signal_lengthsin_vals = tf.
sin(arg_vals) / signal_lengthlosses = []
rmses = []
fori in range(10000):
x = np.random.random([1, signal_length]) - 0.5
withtf.GradientTape() as tape:
y_pred = tf.matmul(x, W_learned)
y_real = y_pred[:, 0:signal_length]
y_imag = y_pred[:, signal_length:]
sinusoids = y_real * cos_vals - y_imag * sin_vals
reconstructed_signal = tf.reduce_sum(sinusoids, axis=1)
loss = tf.reduce_sum(tf.square(x - reconstructed_signal))
W_gradient = tape.gradient(loss, W_learned)
W_learned = tf.Variable(W_learned - 0.5 * W_gradient)
losses.append(loss)
rmses.append(np.sqrt(np.mean((W_learned- W_expected)**2))
Final loss value 4.161919455121241e-22
Final weights' rmse value 0.20243339269590094



作者用这一模型进行了很多测试,最后得到的权重不像上面的例子中那样接近傅里叶权值,但是可以看到重建的信号是一致的。
换成输入振幅和相位试试看呢。
W_learned = tf.Variable(np.random.random([signal_length, 2 * signal_length]) - 0.5)
losses = []
rmses = []
fori in range(10000):
x = np.random.random([1, signal_length]) - .5
withtf.GradientTape() as tape:
y_pred = tf.matmul(x, W_learned)
y_real = y_pred[:, 0:signal_length]
y_imag = y_pred[:, signal_length:]
amplitudes = tf.sqrt(y_real**2 + y_imag**2) / signal_length
phases = tf.atan2(y_imag, y_real)
sinusoids = amplitudes * tf.cos(arg_vals + phases)
reconstructed_signal = tf.reduce_sum(sinusoids, axis=1)
loss = tf.reduce_sum(tf.square(x - reconstructed_signal))
W_gradient = tape.gradient(loss, W_learned)
W_learned = tf.Variable(W_learned - 0.5 * W_gradient)
losses.append(loss)
rmses.append(np.sqrt(np.mean((W_learned- W_expected)**2)))
Final loss value 2.2379359316633115e-21Final weights' rmse value 0.2080118219691059



可以看到,重建信号再次一致;
不过,和此前一样,输入振幅和相位最终得到的权值也不完全等同于傅里叶权值(但非常接近)。
由此可以得出结论,虽然最后得到的权重还不是最准确的,但是也能够获得局部的最优解。
这样一来,神经网络就学会了傅里叶变换!
值得一提的是,这个方法目前还有疑问存在:首先,它没有解释计算出的权值和真正的傅里叶权值相差多少;
而且,也没有说明将傅里叶层放到模型中能带来哪些益处。
原文链接:https://sidsite.com/posts/fourier-nets/
举报/反馈
0
0
收藏
分享
